/* program to print lines backwards */
#include <stdio.h>
# define BUFFERSIZE 80
main()
{
char buffer[BUFFERSIZE];
char *bp; /* a pointer to a character */
int k, j; /* loop induction variables */
bp = buffer;
while ( fgets(buffer, BUFFERSIZE, stdin) != NULL ) {
/* buffer has one line of input */
printf("the line backwards:\n");
/* find the end of the line */
k = 0;
while ( *(buffer+k) != '\0' ) k++;
k--;
if ( (k >= 0) && (*(buffer+k) == '\n') ) k--;
/* print relevant characters in reverse order */
for ( j = k; j >= 0; j-- ) {
printf("%c", *(buffer + j));
}
printf("\n");
}
return(0);
}
Sunday, October 13, 2013
program to print a string backwards
use of array versus pointer references
#include <stdio.h>
# define MAXARRAYSIZE 5
main()
{
int intarray[MAXARRAYSIZE];
int *iap; /* a pointer to an int */
int k; /* loop induction variable */
/* one implementation */
iap = intarray;
for ( k = 0; k < MAXARRAYSIZE; k++) {
*iap = k + 1;
iap++;
}
iap = intarray;
for ( k = 0; k < MAXARRAYSIZE; k++) {
printf("%d\n", *iap);
iap++;
}
/* another implementation */
for ( k = 0; k < MAXARRAYSIZE; k++) {
intarray[k] = k + 1;
}
for ( k = 0; k < MAXARRAYSIZE; k++) {
printf("%d\n", intarray[k]);
}
}
Floating point values
#include <stdio.h>
main()
{
int x; OUTPUT
x = 354;
printf("[%d]\n", x); [354]
printf("[%1d]\n", x); [354]
printf("[%2d]\n", x); [354]
printf("[%3d]\n", x); [354]
printf("[%4d]\n", x); [ 354]
printf("[%-4d]\n", x); [354 ]
}
#include <stdio.h>
main()
{
float x; OUTPUT
x = 1234.5678;
printf("[%f]\n", x); [1234.567749]
printf("[%1f]\n", x); [1234.567749]
printf("[%2f]\n", x); [1234.567749]
printf("[%20f]\n", x); [ 1234.567749]
printf("[%-20f]\n", x); [1234.567749 ]
printf("[%1.2f]\n", x); [1234.57]
printf("[%-2.3f]\n", x); [1234.568]
printf("[%-20.3f]\n", x); [1234.568 ]
}
Two's Complement Multiplication
Here are a couple of ways of doing two's complement multiplication
by hand.
Direct implementations of these algorithms into the circuitry
would result in very slow multiplication!
Actual implementations are far more complex,
and use algorithms that generate more than one bit of product
each clock cycle.
ECE 352 should cover these faster algorithms and implementations.
Remember that the result can require 2 times as many bits as the original operands. We can assume that both operands contain the same number of bits.
A 4-bit, 2's complement example:
To result in the least amount of work, classify which do work, and which do not.
Remember that the result can require 2 times as many bits as the original operands. We can assume that both operands contain the same number of bits.
"No Thinking Method" for Two's Complement Multiplication
In 2's complement, to always get the right answer without thinking about the problem, sign extend both integers to twice as many bits. Then take the correct number of result bits from the least significant portion of the result.A 4-bit, 2's complement example:
1111 1111 -1
x 1111 1001 x -7
---------------- ------
11111111 7
00000000
00000000
11111111
11111111
11111111
11111111
+ 11111111
----------------
1 00000000111
-------- (correct answer underlined)
Another 4-bit, 2's complement example, showing both the
incorrect result (when sign extension is not done),
and the correct result (with sign extension):
WRONG ! Sign extended:
0011 (3) 0000 0011 (3)
x 1011 (-5) x 1111 1011 (-5)
------ -----------
0011 00000011
0011 00000011
0000 00000000
+ 0011 00000011
--------- 00000011
0100001 00000011
not -15 in any 00000011
representation! + 00000011
------------------
1011110001
--------
take the least significant 8 bits 11110001 = -15
"Slightly Less Work Method" for Two's Complement Multiplication
multiplicand
x multiplier
----------------
product
If we do not sign extend the operands (multiplier and multiplicand),
before doing the multiplication, then the wrong answer sometimes
results. To make this work, sign extend the partial products
to the correct number of bits.
To result in the least amount of work, classify which do work, and which do not.
+ - + - (muliplicands)
x + x + x - x - (mulipiers)
---- ---- ---- ----
OK sign | |
extend | take |
partial | additive |
products | inverses |
- +
x + x +
---- ----
sign OK
extend
partial
products
Example:
without with correct
sign extension sign extension
11100 (-4) 11100
x 00011 (3) x 00011
------------ ---------
11100 1111111100
11100 1111111100
------------ ---------------
1010100 (-36) 1111110100 (-12)
WRONG! RIGHT!
Another example:
without adjustment with correct adjustment
11101 (-3) 11101 (-3)
x 11101 (-3) x 11101 (-3)
------------- -------------
11101 (get additive inverse of both)
11101
11101 00011 (+3)
+11101 x 00011 (+3)
----------- -------------
1101001001 (wrong!) 00011
+ 00011
---------
001001 (+9) (right!)
Floating Point Representation
Computers represent real values in a form similar to that of
scientific notation.
Consider the value
1.23 x 10^4
The number has a sign (+ in this case)
The significand (1.23) is written with one non-zero digit to the left of the decimal point.
The base (radix) is 10.
The exponent (an integer value) is 4. It too must have a sign.
There are standards which define what the representation means, so that across computers there will be consistancy.
Note that this is not the only way to represent floating point numbers, it is just the IEEE standard way of doing it.
Here is what we do:
the representation has three fields:
S is one bit representing the sign of the number
E is an 8-bit biased integer representing the exponent
F is an unsigned integer the decimal value represented is:
n = 23
bias = 127
for double precision representation (a 64-bit representation)
n = 52 (there are 52 bits for the mantissa field)
bias = 1023 (there are 11 bits for the exponent field)
An integer representation that skews the bit patterns so as to look just like unsigned but actually represent negative numbers.
It represents a range of values (different from unsigned representation) using the unsigned representation. Another way of saying this: biased representation is a re-mapping of the unsigned integers.
visual example (of the re-mapping):
Given 4 bits, bias values by 2**3 = 8
(This choice of bias results in approximately half the represented values being negative.)
The bias chosen is most often based on the number of bits available for representing an integer. To get an approx. equal distribution of values above and below 0, the bias should be
Now, what does all this mean?
1.23 x 10^4
The number has a sign (+ in this case)
The significand (1.23) is written with one non-zero digit to the left of the decimal point.
The base (radix) is 10.
The exponent (an integer value) is 4. It too must have a sign.
There are standards which define what the representation means, so that across computers there will be consistancy.
Note that this is not the only way to represent floating point numbers, it is just the IEEE standard way of doing it.
Here is what we do:
the representation has three fields:
----------------------------
| S | E | F |
----------------------------
S is one bit representing the sign of the number
E is an 8-bit biased integer representing the exponent
F is an unsigned integer the decimal value represented is:
S e (-1) x f x 2where
e = E - bias
f = ( F/(2^n) ) + 1
for single precision representation (the emphasis in this class)
n = 23
bias = 127
for double precision representation (a 64-bit representation)
n = 52 (there are 52 bits for the mantissa field)
bias = 1023 (there are 11 bits for the exponent field)
Biased Integer Representation
Since floating point representations use biased integer representations for the exponent field, here is a brief discussion of biased integers.An integer representation that skews the bit patterns so as to look just like unsigned but actually represent negative numbers.
It represents a range of values (different from unsigned representation) using the unsigned representation. Another way of saying this: biased representation is a re-mapping of the unsigned integers.
visual example (of the re-mapping):
bit pattern: 000 001 010 011 100 101 110 111
unsigned value: 0 1 2 3 4 5 6 7
biased-2 value: -2 -1 0 1 2 3 4 5
This is biased-2. Note the dash character in the name
of this representation. It is not a negative sign.
Example:
Given 4 bits, bias values by 2**3 = 8
(This choice of bias results in approximately half the represented values being negative.)
TRUE VALUE to be represented 3
add in the bias +8
----
unsigned value 11
so the 4-bit, biased-8 representation of the value 3
will be 1011
Example:
Going the other way, suppose we were given a
4-bit, biased-8 representation of 0110
unsigned 0110 represents 6
subtract out the bias - 8
----
TRUE VALUE represented -2
On choosing a bias:
The bias chosen is most often based on the number of bits available for representing an integer. To get an approx. equal distribution of values above and below 0, the bias should be
2 ^ (n-1) or (2^(n-1)) - 1
Now, what does all this mean?
- S, E, F all represent fields within a representation. Each is just a bunch of bits.
- S is just a sign bit. 0 for positive, 1 for negative. This is the sign of the number.
- E is an exponent field. The E field is a biased-127 integer representation. So, the true exponent represented is (E - bias).
-
The radix for the number is ALWAYS 2.
Note: Computers that did not use this representation, like those built before the standard, did not always use a radix of 2. For example, some IBM machines had radix of 16. -
F is the mantissa (significand). It is in a somewhat modified form.
There are 23 bits available for the mantissa.
It turns out that if floating point numbers are always stored in their normalized form,
then the leading bit (the one on the left, or MSB) is ALWAYS a 1.
So, why store it at all?
It gets put back into the number (giving 24 bits of precision for the mantissa)
for any calculation, but we only have to store 23 bits.
This MSB is called the hidden bit.
first step:
get a binary representation for 64.2
to do this, get unsigned binary representations for the stuff to the left
and right of the decimal point separately.
64 is 1000000
.2 can be gotten using the algorithm:
.2 x 2 = 0.4 0
.4 x 2 = 0.8 0
.8 x 2 = 1.6 1
.6 x 2 = 1.2 1
.2 x 2 = 0.4 0 now this whole pattern (0011) repeats.
.4 x 2 = 0.8 0
.8 x 2 = 1.6 1
.6 x 2 = 1.2 1
so a binary representation for .2 is .001100110011. . .
----
or .0011 (The bar over the top shows which bits repeat.)
Putting the halves back together again:
64.2 is 1000000.0011001100110011. . .
second step:
Normalize the binary representation. (make it look like
scientific notation)
6
1.000000 00110011. . . x 2
third step:
6 is the true exponent. For the standard form, it needs to
be in 8-bit, biased-127 representation.
6
+ 127
-----
133
133 in 8-bit, unsigned representation is 1000 0101
This is the bit pattern used for E in the standard form.
fourth step:
the mantissa stored (F) is the stuff to the right of the radix point
in the normalized form. We need 23 bits of it.
000000 00110011001100110
put it all together (and include the correct sign bit):
S E F
0 10000101 00000000110011001100110
the values are often given in hex, so here it is
0100 0010 1000 0000 0110 0110 0110 0110
0x 4 2 8 0 6 6 6 6
Some extra details:
-
Since floating point numbers are always stored in a normalized
form, how do we represent 0?
We take the bit patterns 0x0000 0000 and 0x8000 0000
to represent the value 0.
(What floating point numbers cannot be represented because of this?)
Note that the hardware that does arithmetic on floating point numbers must be constantly checking to see if it needs to use a hidden bit of a 1 or a hidden bit of 0 (for 0.0).
Values that are very close to 0.0, and would require the hidden bit to be a zero are called denormalized or subnormal numbers.
S E F 0.0 0 or 1 00000000 00000000000000000000000 (hidden bit is a 0) subnormal 0 or 1 00000000 not all zeros (hidden bit is a 0) normalized 0 or 1 > 0 any bit pattern (hidden bit is a 1) -
Other special values:
S E F +infinity 0 11111111 00000... (0x7f80 0000) -infinity 1 11111111 00000... (0xff80 0000) NaN (Not a Number) ? 11111111 ?????... (S is either 0 or 1, E=0xff, and F is anything but all zeros) -
Single precision representation is 32 bits.
Double precision representation is 64 bits. For double precision:
- S is the sign bit (same as for single precision).
- E is an 11-bit, biased-1023 integer for the exponent.
- F is a 52-bit mantissa, using same method as single precision (hidden bit is not expicit in the representation).
arithmetic operations on floating point numbers consist of addition, subtraction, multiplication and division the operations are done with algorithms similar to those used on sign magnitude integers (because of the similarity of representation) -- example, only add numbers of the same sign. If the numbers are of opposite sign, must do subtraction.
Addition
example on decimal value given in scientific notation: 3.25 x 10 ** 3 + 2.63 x 10 ** -1 ----------------- first step: align decimal points second step: add 3.25 x 10 ** 3 + 0.000263 x 10 ** 3 -------------------- 3.250263 x 10 ** 3 (presumes use of infinite precision, without regard for accuracy) third step: normalize the result (already normalized!) example on fl pt. value given in binary: S E F .25 = 0 01111101 00000000000000000000000 100 = 0 10000101 10010000000000000000000 to add these fl. pt. representations, step 1: align radix points shifting the mantissa LEFT by 1 bit DECREASES THE EXPONENT by 1 shifting the mantissa RIGHT by 1 bit INCREASES THE EXPONENT by 1 we want to shift the mantissa right, because the bits that fall off the end should come from the least significant end of the mantissa -> choose to shift the .25, since we want to increase it's exponent. -> shift by 10000101 -01111101 --------- 00001000 (8) places. with hidden bit and radix point shown, for clarity: 0 01111101 1.00000000000000000000000 (original value) 0 01111110 0.10000000000000000000000 (shifted 1 place) (note that hidden bit is shifted into msb of mantissa) 0 01111111 0.01000000000000000000000 (shifted 2 places) 0 10000000 0.00100000000000000000000 (shifted 3 places) 0 10000001 0.00010000000000000000000 (shifted 4 places) 0 10000010 0.00001000000000000000000 (shifted 5 places) 0 10000011 0.00000100000000000000000 (shifted 6 places) 0 10000100 0.00000010000000000000000 (shifted 7 places) 0 10000101 0.00000001000000000000000 (shifted 8 places) step 2: add (don't forget the hidden bit for the 100) 0 10000101 1.10010000000000000000000 (100) + 0 10000101 0.00000001000000000000000 (.25) --------------------------------------- 0 10000101 1.10010001000000000000000 step 3: normalize the result (get the "hidden bit" to be a 1) it already is for this example. result is 0 10000101 10010001000000000000000 suppose that the result of an addition of aligned mantissas gives 10.11110000000000000000000 and the exponent to go with this is 10000000. We must put the mantissa back in the normalized form. Shift the mantissa to the right by one place, and increase the exponent by 1. The exponent and mantissa become 10000001 1.01111000000000000000000 0 (1 bit is lost off the least significant end)Subtraction
like addition as far as alignment of radix points then the algorithm for subtraction of sign mag. numbers takes over. before subtracting, compare magnitudes (don't forget the hidden bit!) change sign bit if order of operands is changed. don't forget to normalize number afterward. EXAMPLE: 0 10000001 10010001000000000000000 (the representations) - 0 10000000 11100000000000000000000 --------------------------------------- step 1: align radix points 0 10000000 11100000000000000000000 becomes 0 10000001 11110000000000000000000 (notice hidden bit shifted in) 0 10000001 1.10010001000000000000000 - 0 10000001 0.11110000000000000000000 --------------------------------------- step 2: subtract mantissa 1.10010001000000000000000 - 0.11110000000000000000000 ------------------------------- 0.10100001000000000000000 step 3: put result in normalized form Shift mantissa left by 1 place, implying a subtraction of 1 from the exponent. 0 10000000 01000010000000000000000Multiplication
example on decimal values given in scientific notation: 3.0 x 10 ** 1 + 0.5 x 10 ** 2 ----------------- algorithm: multiply mantissas (use unsigned multiplication) add exponents 3.0 x 10 ** 1 + 0.5 x 10 ** 2 ----------------- 1.50 x 10 ** 3 example in binary: use a mantissa that is only 4 bits as an example 0 10000100 0100 x 1 00111100 1100 ----------------- The multiplication is unsigned multiplication (NOT two's complement), so, make sure that all bits are included in the answer. Do NOT do any sign extension! mantissa multiplication: 1.0100 (don't forget hidden bit) x 1.1100 ------ 00000 00000 10100 10100 10100 --------- 1000110000 becomes 10.00110000 add exponents: always add true exponents (otherwise the bias gets added in twice) biased: 10000100 + 00111100 ---------- 10000100 01111111 (switch the order of the subtraction, - 01111111 - 00111100 so that we can get a negative value) ---------- ---------- 00000101 01000011 true exp true exp is 5. is -67 add true exponents 5 + (-67) is -62. re-bias exponent: -62 + 127 is 65. unsigned representation for 65 is 01000001. put the result back together (and add sign bit). 1 01000001 10.00110000 normalize the result: (moving the radix point one place to the left increases the exponent by 1. Can also think of this as a logical right shift.) 1 01000001 10.00110000 becomes 1 01000010 1.000110000 this is the value stored (not the hidden bit!): 1 01000010 000110000Division
similar to multiplication. true division: do unsigned division on the mantissas (don't forget the hidden bit) subtract TRUE exponents The IEEE standard is very specific about how all this is done. Unfortunately, the hardware to do all this is pretty slow. Some comparisons of approximate times: 2's complement integer add 1 time unit fl. pt add 4 time units fl. pt multiply 6 time units fl. pt. divide 13 time units There is a faster way to do division. Its called division by reciprocal approximation. It takes about the same time as a fl. pt. multiply. Unfortunately, the results are not always correct. Division by reciprocal approximation: instead of doing a / b they do a x 1/b. figure out a reciprocal for b, and then use the fl. pt. multiplication hardware. example of a result that isn't the same as with true division. true division: 3/3 = 1 (exactly) reciprocal approx: 1/3 = .33333333 3 x .33333333 = .99999999, not 1 It is not always possible to get a perfectly accurate reciprocal. Current fastest (and correct) division algorithm is called SRT Sweeney, Robertson, and Tocher Uses redundant quotient representation E.g., base 4 usually has digits {0,1,2,3} SRT's redundant base 4 has digits {-2,-1,0,+1,+2} Allows division algorithm to guess digits approximately with a table lookup. Approximations are fixed up when less-sigificant digits are calculated Final result in completely-accurate binary. In 1994, Intel got a few corner cases of the table wrong Maximum error less than one part in 10,000 Nevertheless, Intel took a $300M write-off to replace chip Compare with software bugs that give the wrong answer and the customer pays for the upgradeIssues in Floating Point
note: this discussion only touches the surface of some issues that people deal with. Entire courses are taught on floating point arithmetic. use of standards ---------------- --> allows all machines following the standard to exchange data and to calculate the exact same results. --> IEEE fl. pt. standard sets parameters of data representation (# bits for mantissa vs. exponent) --> MIPS architecture follows the standard (All architectures follow the standard now.) overflow and underflow ---------------------- Just as with integer arithmetic, floating point arithmetic operations can cause overflow. Detection of overflow in fl. pt. comes by checking exponents before/during normalization. Once overflow has occurred, an infinity value can be represented and propagated through a calculation. Underflow occurs in fl. pt. representations when a number is to small (close to 0) to be represented. (show number line!) if a fl. pt. value cannot be normalized (getting a 1 just to the left of the radix point would cause the exponent field to be all 0's) then underflow occurs. Underflow may result in the representation of denormalized values. These are ones in which the hidden bit is a 0. The exponent field will also be all 0s in this case. Note that there would be a reduced precision for representing the mantissa (less than 23 bits to the right of the radix point). Defining the results of certain operations ------------------------------------------ Many operations result in values that cannot be represented. Other operations have undefined results. Here is a list of some operations and their results as defined in the standard. 1/0 = infinity any positive value / 0 = positive infinity any negative value / 0 = negative infinity infinity * x = infinity 1/infinity = 0 0/0 = NaN 0 * infinity = NaN infinity * infinity = NaN infinity - infinity = NaN infinity/infinity = NaN x + NaN = NaN NaN + x = NaN x - NaN = NaN NaN - x = NaN sqrt(negative value) = NaN NaN * x = NaN NaN * 0 = NaN 1/NaN = NaN (Any operation on a NaN produces a NaN.) HW vs. SW computing ------------------- floating point operations can be done by hardware (circuitry) or by software (program code). -> a programmer won't know which is occuring, without prior knowledge of the HW. -> SW is much slower than HW. by approx. 1000 times. A difficult (but good) exercize for students would be to design a SW algorithm for doing fl. pt. addition using only integer operations. SW to do fl. pt. operations is tedious. It takes lots of shifting and masking to get the data in the right form to use integer arithmetic operations to get a result -- and then more shifting and masking to put the number back into fl. pt. format. A common thing for manufacturers to do is to offer 2 versions of the same architecture, one with HW, and the other with SW fl. pt. ops.on Rounding
arithmetic operations on fl. pt. values compute results that cannot be represented in the given amount of precision. So, we round results. There are MANY ways of rounding. They each have "correct" uses, and exist for different reasons. The goal in a computation is to have the computer round such that the end result is as "correct" as possible. There are even arguments as to what is really correct. First, how do we get more digits (bits) than were in the representation? The IEEE standard requires the use of 3 extra bits of less significance than the 24 bits (of mantissa) implied in the single precision representation. mantissa format plus extra bits: 1.XXXXXXXXXXXXXXXXXXXXXXX 0 0 0 ^ ^ ^ ^ ^ | | | | | | | | | - sticky bit (s) | | | - round bit (r) | | - guard bit (g) | - 23 bit mantissa from a representation - hidden bit This is the format used internally (on many, not all processors) for a single precision floating point value. When a mantissa is to be shifted in order to align radix points, the bits that fall off the least significant end of the mantissa go into these extra bits (guard, round, and sticky bits). These bits can also be set by the normalization step in multiplication, and by extra bits of quotient (remainder?) in division. The guard and round bits are just 2 extra bits of precision that are used in calculations. The sticky bit is an indication of what is/could be in lesser significant bits that are not kept. If a value of 1 ever is shifted into the sticky bit position, that sticky bit remains a 1 ("sticks" at 1), despite further shifts. Example: mantissa from representation, 11000000000000000000100 must be shifted by 8 places (to align radix points) g r s Before first shift: 1.11000000000000000000100 0 0 0 After 1 shift: 0.11100000000000000000010 0 0 0 After 2 shifts: 0.01110000000000000000001 0 0 0 After 3 shifts: 0.00111000000000000000000 1 0 0 After 4 shifts: 0.00011100000000000000000 0 1 0 After 5 shifts: 0.00001110000000000000000 0 0 1 After 6 shifts: 0.00000111000000000000000 0 0 1 After 7 shifts: 0.00000011100000000000000 0 0 1 After 8 shifts: 0.00000001110000000000000 0 0 1 The IEEE standard for floating point arithmetic requires that the programmer be allowed to choose 1 of 4 methods for rounding: Method 1. round toward 0 (also called truncation) figure out how many bits (digits) are available. Take that many bits (digits) for the result and throw away the rest. This has the effect of making the value represented closer to 0.0 example in decimal: .7783 if 3 decimal places available, .778 if 2 decimal places available, .77 if 1 decimal place available, .7 examples in binary, where only 2 bits are available to the right of the radix point: (underlined value is the representation chosen) 1.1101 | 1.11 | 10.00 ------ 1.001 | 1.00 | 1.01 ----- -1.1101 | -10.00 | -1.11 ------ -1.001 | -1.01 | -1.00 ----- With results from floating point calculations that generate guard, round, and sticky bits, just leave them off. Note that this is VERY easy to implement! examples in the floating point format with guard, round and sticky bits: g r s 1.11000000000000000000100 0 0 0 1.11000000000000000000100 (mantissa used) 1.11000000000000000000110 1 1 0 1.11000000000000000000110 (mantissa used) 1.00000000000000000000111 0 1 1 1.00000000000000000000111 (mantissa used) Method 2. round toward positive infinity regardless of the value, round towards +infinity. example in decimal: 1.23 if 2 decimal places, 1.3 -2.86 if 2 decimal places, -2.8 examples in binary, where only 2 bits are available to the right of the radix point: 1.1101 | 1.11 | 10.00 ------ 1.001 | 1.00 | 1.01 ----- examples in the floating point format with guard, round and sticky bits: g r s 1.11000000000000000000100 0 0 0 1.11000000000000000000100 (mantissa used, exact representation) 1.11000000000000000000100 1 0 0 1.11000000000000000000101 (rounded "up") -1.11000000000000000000100 1 0 0 -1.11000000000000000000100 (rounded "up") 1.11000000000000000000001 0 1 0 1.11000000000000000000010 (rounded "up") 1.11000000000000000000001 0 0 1 1.11000000000000000000010 (rounded "up") Method 3. round toward negative infinity regardless of the value, round towards -infinity. example in decimal: 1.23 if 2 decimal places, 1.2 -2.86 if 2 decimal places, -2.9 examples in binary, where only 2 bits are available to the right of the radix point: 1.1101 | 1.11 | 10.00 ------ 1.001 | 1.00 | 1.01 ----- examples in the floating point format with guard, round and sticky bits: g r s 1.11000000000000000000100 0 0 0 1.11000000000000000000100 (mantissa used, exact representation) 1.11000000000000000000100 1 0 0 1.11000000000000000000100 (rounded "down") -1.11000000000000000000100 1 0 0 -1.11000000000000000000101 (rounded "down") Method 4. round to nearest use representation NEAREST to the desired value. This works fine in all but 1 case: where the desired value is exactly half way between the two possible representations. The half way case: 1000... to the right of the number of digits to be kept, then round toward nearest uses the representation that has zero as its least significant bit. Examples: 1.1111 (1/4 of the way between, one is nearest) | 1.11 | 10.00 ------ 1.1101 (1/4 of the way between, one is nearest) | 1.11 | 10.00 ------ 1.001 (the case of exactly halfway between) | 1.00 | 1.01 ----- -1.1101 (1/4 of the way between, one is nearest) | -10.00 | -1.11 ------ -1.001 (the case of exactly halfway between) | -1.01 | -1.00 ----- NOTE: this is a bit different than the "round to nearest" algorithm (for the "tie" case, .5) learned in elementary school for decimal numbers. examples in the floating point format with guard, round and sticky bits: g r s 1.11000000000000000000100 0 0 0 1.11000000000000000000100 (mantissa used, exact representation) 1.11000000000000000000000 1 1 0 1.11000000000000000000001 1.11000000000000000000000 0 1 0 1.11000000000000000000000 1.11000000000000000000000 1 1 1 1.11000000000000000000001 1.11000000000000000000000 0 0 1 1.11000000000000000000000 1.11000000000000000000000 1 0 0 (the "halfway" case) 1.11000000000000000000000 (lsb is a zero) 1.11000000000000000000001 1 0 0 (the "halfway" case) 1.11000000000000000000010 (lsb is a zero) A complete example of addition, using rounding. S E F 1 10000000 11000000000000000011111 + 1 10000010 11100000000000000001001 ------------------------------------------- First, align the radix points by shifting the top value's mantissa 2 places to the right (increasing the exponent by 2) S E mantissa (+h.b) g r s 1 10000000 1.11000000000000000011111 0 0 0 (before shifting) 1 10000001 0.11100000000000000001111 1 0 0 (after 1 shift) 1 10000010 0.01110000000000000000111 1 1 0 (after 2 shifts) Add mantissas 1.11100000000000000001001 0 0 0 + 0.01110000000000000000111 1 1 0 -------------------------------------- 10.01010000000000000010000 1 1 0 This must now be put back in the normalized form, E mantissa g r s 10000010 10.01010000000000000010000 1 1 0 (shift mantissa right by 1 place, causing the exponent to increase by 1) 10000011 1.00101000000000000001000 0 1 1 S E mantissa g r s 1 10000011 1.00101000000000000001000 0 1 1 Now, we round. If round toward zero, 1 10000011 1.00101000000000000001000 giving a representation of 1 10000011 00101000000000000001000 in hexadecimal: 1100 0001 1001 0100 0000 0000 0000 1000 0x c 1 9 4 0 0 0 8 If round toward +infinity, 1 10000011 1.00101000000000000001000 giving a representation of 1 10000011 00101000000000000001000 in hexadecimal: 1100 0001 1001 0100 0000 0000 0000 1000 0x c 1 9 4 0 0 0 8 If round toward -infinity, 1 10000011 1.00101000000000000001001 giving a representation of 1 10000011 00101000000000000001001 in hexadecimal: 1100 0001 1001 0100 0000 0000 0000 1001 0x c 1 9 4 0 0 0 9 If round to nearest, 1 10000011 1.00101000000000000001000 giving a representation of 1 10000011 00101000000000000001000 in hexadecimal: 1100 0001 1001 0100 0000 0000 0000 1000 0x c 1 9 4 0 0 0 8 A diagram to help with rounding when doing floating point multiplication. [ ] X [ ] -------------------- [ ] [ ][ ][ ] result in the g r combined to given produce precision a sticky bit
Instruction Level Parallelism: Pipelining
Programmer's model: one instruction is fetched and executed at
a time.
Computer architect's model: The effect of a program's execution are given by the programmer's model. But, implementation may be different.
To make execution of programs faster, we attempt to exploit parallelism: doing more than one thing at one time.
A task is broken down into steps. Assume that there are N steps, each takes the same amount of time.
(Mark Hill's) EXAMPLE: car wash
Two very important terms when discussing pipelining:
Pipelining can be done in computer hardware.
2-stage pipeline
A popular pipelined implementation:
(Note: the R2000/3000 has 5 stages, the R6000 has 5 stages (but different), and the R4000 has 8 stages)
Data dependencies
Suppose we have the following code:
Classification of data dependencies:
Control dependencies
What happens to a pipeline in the case of branch instructions?
MAL CODE SEQUENCE:
Control dependencies break pipelines. They cause performance to plummet.
So, lots of (partial) solutions have been implemented to try to help the situation. Worst case, the pipeline must be stalled such that instructions are going through sequentially.
Note that just stalling does not really help, since the (potentially) wrong instruction is fetched before it is determined that the previous instruction is a branch.
How to minimize the effect of control dependencies on pipelines.
A historically significant way of branching. Condition codes were used on MANY machines before pipelining became popular.
4 1-bit registers (condition code register):
Example:
Earlier computers had virtually every instruction set the condition codes. This had the effect that the test (for the branch) needed to come directly before the branch.
Example:
Computer architect's model: The effect of a program's execution are given by the programmer's model. But, implementation may be different.
To make execution of programs faster, we attempt to exploit parallelism: doing more than one thing at one time.
- program level parallelism: Have one program run parts of itself on more than one computer. The different parts occasionally synch up (if needed), but they run at the same time.
- instruction level parallelism (ILP): Have more than one instruction within a single program executing at the same time.
Pipelining (ILP)
The concept:A task is broken down into steps. Assume that there are N steps, each takes the same amount of time.
(Mark Hill's) EXAMPLE: car wash
steps: P -- prep
W -- wash
R -- rinse
D -- dry
X -- wax
assume each step takes 1 time unit
time to wash 1 car (red) = 5 time units
time to wash 3 cars (red, green, blue) = 15 time units
which car time units
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
red P W R D X
green P W R D X
blue P W R D X
A pipeline overlaps the steps.
which car time units
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
red P W R D X
green P W R D X
blue P W R D X
yellow P W R D X
etc.
IT STILL TAKES 5 TIME UNITS TO WASH 1 CAR,
BUT THE RATE OF CAR WASHES GOES UP!
Two very important terms when discussing pipelining:
- latency: The time it takes (from beginning to end) to complete a task.
- throughput: The rate of task completions.
Pipelining can be done in computer hardware.
2-stage pipeline
steps:
F -- instruction fetch (and PC update!)
E -- instruction execute (everything else)
which instruction time units
1 2 3 4 5 6 7 8 . . .
1 F E
2 F E
3 F E
4 F E
time for 1 instruction = 2 time units
(INSTRUCTION LATENCY)
rate of instruction execution = pipeline depth * (1 / time for )
(INSTRUCTION THROUGHPUT) 1 instruction
= 2 * (1 / 2)
= 1 per time unit
5-stage pipeline
A popular pipelined implementation:
(Note: the R2000/3000 has 5 stages, the R6000 has 5 stages (but different), and the R4000 has 8 stages)
steps:
IF -- instruction fetch (and PC update)
ID -- instruction decode (and get operands from registers)
EX -- ALU operation (can be effective address calculation)
MA -- memory access
WB -- write back (results written to register(s))
which time units
instruction 1 2 3 4 5 6 7 8 . . .
1 IF ID EX MA WB
2 IF ID EX MA WB
3 IF ID EX MA WB
INSTRUCTION LATENCY = 5 time units
INSTRUCTION THROUGHPUT = 5 * (1 / 5) = 1 instruction per time unit
Unfortunately, pipelining introduces other difficulties. . .
Data dependencies
Suppose we have the following code:
lw $8, data1
addi $9, $8, 1
The data loaded does not get written to $8 until WB,
but the addi instruction wants to get the data out of $8
it its ID stage. . .
which time units
instruction 1 2 3 4 5 6 7 8 . . .
lw IF ID EX MA WB
^^
addi IF ID EX MA WB
^^
The simplest solution is to STALL the pipeline.
(Also called HOLES, HICCOUGHS or BUBBLES in the pipe.)
which time units
instruction 1 2 3 4 5 6 7 8 . . .
lw IF ID EX MA WB
^^
addi IF ID ID ID EX MA WB
^^ ^^ ^^ (pipeline stalling)
A data dependency (also called a hazard) causes performance to
decrease.
Classification of data dependencies:
- Read After Write (RAW), the example given. A read of data is needed before it has been written.
- Write After Read (WAR). Given for completeness, not a difficulty to current pipelines in practice, since the only writing occurs as the last stage.
- Write After Write (WAR). Given for completeness, not a difficulty to current pipelines in practice, since the only writing occurs as the last stage.
Control dependencies
What happens to a pipeline in the case of branch instructions?
MAL CODE SEQUENCE:
b label1
addi $9, $8, 1
label1: mult $8, $9
which time units
instruction 1 2 3 4 5 6 7 8 . . .
b IF ID EX MA WB
^^ (PC changed here)
addi IF ID EX MA WB
^^ (WRONG instruction fetched here!)
Whenever the PC changes (except for PC <- PC + 4),
we have a control dependency.
Control dependencies break pipelines. They cause performance to plummet.
So, lots of (partial) solutions have been implemented to try to help the situation. Worst case, the pipeline must be stalled such that instructions are going through sequentially.
Note that just stalling does not really help, since the (potentially) wrong instruction is fetched before it is determined that the previous instruction is a branch.
How to minimize the effect of control dependencies on pipelines.
-
Easiest solution (poor performance):
Cancel anything (later) in the pipe when a branch (jump) is decoded. This works as long as nothing changes the program's state before the cancellation. Then let the branch instruction finish ("flush the pipe"), and start up again.which time units instruction 1 2 3 4 5 6 7 8 . . . b IF ID EX MA WB ^^ (PC changed here) addi IF mult ^^ (cancelled) IF ID EX MA WB -
branch Prediction (static or dynamic):
Add lots of extra hardware to try to help.-
static branch prediction
Assume that the branch will not be taken.
When the decision is made, the hw "knows" if the correct instruction has been partially executed. If the correct instruction is currently in the pipe, let it (and all those after it) continue. Then, there will be NO holes in the pipe. If the incorrect instruction is currently in the pipe, (meaning that the branch was taken), then all instructions currently in the pipe subsequent to the branch must be BACKED OUT.
NOTE: static branch prediction works quite well with currently popular pipeline solutions, because no state information is changed until the very last stage of an instruction. As long as the last stage has not started, backing out is a matter of stopping the last stage from occuring and getting the PC right. -
dynamic branch prediction
Have some extra hw that keeps track of which branches have been taken in the recent past. Design the hw to presume that a branch will be taken the same way it was previously. If the guess is wrong, back out as in static branch prediction.
-
static branch prediction
-
separate the test from the branch
Make the conditional test and address calculation separate instructions from the one that changes the PC. This reduces the number of holes in the pipe. -
delayed branch,
the MIPS solution.
The concept: prediction is always wrong
sometime. There will be holes in the pipe when the prediction
is wrong. So the goal is to reduce (eliminate?) the number of
holes in the case of a branch.
The mechanism:
Have the effect of a branch (the change of the PC) be delayed until a subsequent instruction. This means that the instruction following a branch is executed independent of whether the branch is to be taken or not.
(NOTE: the simulator completely ignores this delayed branch mechanism!)
code example:
Note that in this code example, we want one of two possibilities for the code that gets executed:add $8, $9, $10 beq $3, $4, label move $18, $5 . . . label: sub $20, $21, $22
1) add $8, $9, $10 beq $3, $4, label move $18, $5 or 2) add $8, $9, $10 beq $3, $4, label sub $20, $21, $22In both cases, the add and beq instructions are executed.
The code is turned into the following by a MIPS assembler:
If the assembler has any smarts at all, it would REARRANGE the code to beadd $8, $9, $10 beq $3, $4, label nop # really a pipeline hole, the DELAY SLOT move $18, $5 . . . label: sub $20, $21, $22
This code can be rearranged only if there are no data dependencies between the branch and the add instructions. In fact, any instruction from before the branch (and after any previous branch) can be moved into the DELAY SLOT, as long as there are no dependencies on it.beq $3, $4, label add $8, $9, $10 move $18, $5 . . . label: sub $20, $21, $22
Delayed branching depends on a smart assembler (sw) to make the hardware perform at peak efficiency. This is a general trend in the field of computer science. Let the sw do more and more to improve performance of the hw.
A historically significant way of branching. Condition codes were used on MANY machines before pipelining became popular.
4 1-bit registers (condition code register):
- N -- negative
- V -- overflow
- P -- positive
- Z -- zero
Example:
bn label # branch to label if the N bit is set
Earlier computers had virtually every instruction set the condition codes. This had the effect that the test (for the branch) needed to come directly before the branch.
Example:
sub r3, r4, r5 # blt $4, $5, label
bn label
A performance improvement (sometimes) to this allowed the
programmer to explicitly specify which instructions should
set the condition codes. In this way, (on a pipelined machine)
the test could be separated from the branch, resulting in
fewer pipeline holes due to data dependencies.
Sunday, October 6, 2013
Survey of Operating Systems
2.1. Early Operating Systems (1940s).
Recall from the in-class discussion of history of
computers that Charles Babbage and others who developed purely
mechanical computers did not have to worry about an operating system.
The computational hardware had fixed functionality, and only one
computation could run at any given time. Furthermore, programming as
we know it did not exist. Thus, there was no operating system to
interface the user to the bare machine.
The early electronic computers developed by Charles
Atanasoff at Iowa State, as well as Aitken at Princeton, Mauchly and
Eckert at the University of Pennsylvania, and Zuse in Germany used
electronic components. However, the Princeton and Penn State
machines, which were based on vacuum tubes and relays, were complete
working machines during the WWII period. In contrast, Atanasoff's
machine was used prior to WWII to solve systems of differential
equations, and Zuse's machine only worked in part. These machines
were programmed with plugboards that encoded a form of machine
language. High-level programming languages and operating systems had
not yet been discovered.
On these early vacuum-tube machines, a programmer
would run a program by inserting his plugboard(s) into a rack, then
turning on the machine and hoping that none of the vacuum tubes would
die during the computation. Most of the computations were numerical,
for example, tables of sine, cosine, or logarithm functions. In WWII,
these machines were used to calculate artillery trajectories. It is
interesting to note that the Generation 1 computers produced results
at a slower rate than today's hand-held calculators.
2.2. Growth of Operating System Concepts (1950s)
By the early 1950s, punch-card input had been
developed, and there was a wide variety of machinery that supported
the punching (both manual and automatic) and reading of card decks.
The programmer would take his or her deck to the operator, who would
insert it into the reader, and the program would be loaded into the
machine. Computation would ensue, without other tasks being
performed. This was more flexible than using plugboards, but most
programming was done in machine language (ones and zeroes).
Otherwise, the procedure was identical to the plugboard machines of
the 1940s.
In 1947, the transistor was invented at Bell
Laboratories. Within several years, transistorized electronic
equipment was being produced in commercial quantity. This led
computer designers to speculate on the use of transistor-based
circuitry for computation. By 1955, computers were using transistor
circuits, which were more reliable, smaller, and less
power-consumptive than vacuum tubes. As a result, a small number of
computers were produced and sold commercially, but at enormous cost
per machine.
Definition. A job is a program or collection of programs to be run on a computing machine.Definition. A job queue is a list of waiting jobs.
The early transistor machines required that a job be
submitted well in advance of being run. The operator would run the
card deck through the reader, load the job on tape, load the tape into
the computer, run the computer, get the printout from the printer, and
put the printout in the user's or programmer's mailbox. All this
human effort took time that was large in relationship to the time
spent running each job on the computer. If ancillary software (e.g.,
a FORTRAN or COBOL compiler) was required, the operator would have to
spend more time retrieving the compiler's card deck from a filing
cabinet and reading it in to the machine, prior to actual computation.
At this time, a few businesses were using computers
to track inventory and payroll, as well as to conduct research in
process optimization. The business leaders who had payed great sums
of money for computers were chagrined that so much human effort was
required to initiate and complete jobs, while the expensive machine
sat idle. The first solution to this largely economic problem was
batch processing.
Definition. A batch processing system is a system that processes collections of multiple jobs, one collection at a time. This processing does not occur in real time, but the jobs are collected for a time before they are processed.Definition. Off line processing consists of tasks performed by an ancillary machine not connected to the main computer.Definition. A scratch tape or scratch disk is a separate tape/disk device or disk partition used for temporary storage, i.e., like a physical scratchpad.
Batch processing used a small, inexpensive machine to
input and collect jobs. The jobs were read onto magnetic tape, which
implemented a primitive type of job queue. When the reel of
tape was full of input, an operator would take the reel to the main
computer and load it onto the main computer's tape drive. The main
computer would compute the jobs, and write the results to another tape
drive. After the batch was computed, the output tape would be taken
to another small, inexpensive computer that was connected to the
printer or to a card punch. The output would be produced by this
third computer. The first and third computers performed off-line
processing in input and output mode, respectively. This approach
greatly decreased the time operators dedicated to each job.
However, the main computer needed to know what jobs
were being input to its tape drive, and what were the requirements of
those jobs. So, a system of punched card identifiers was developed
served as input to a primitive operating system which in turn replaced
the operator's actions in loading programs, compilers, and data into
the computer.
For example, a COBOL program with some input data
would have cards arranged in the following partitions:
$JOBCard: Specified maximum runtime, account to be charged, and programmer's name$COBOLCard: Instructed computer to load the COBOL compiler from a system tape drive connected to the main computer- Program: A stack of punched cards that contained COBOL instructions comprising a program, which was compiled and written in the form of object code to a scratch tape
$LOADCard: Instructed computer to load the compiled program into memory from scratch tape$RUNCard: Instructed computer to run the program, with data (if any) that followed the $RUN card- Data: If present, data were encoded on one or more punched cards and were read in on an as-needed basis. The primitive operating system also controlled the tape drive that read in the data.
$ENDCard: Specified the end of a job. This was required to keep the computer from running the scratch tape(s) and output tape(s) when there was no computation being performed.
These sequences of job control cards were
forerunners of Job Control Language (JCL) and command-based operating
systems. Since large second-generation computers were used primarily
for scientific calculations, they were largely programmed in FORTRAN.
Examples of early operating systems were the FORTRAN Monitor System
(FMS) and IBSYS, which was IBM's operating system for its scientific
computer, the Model 7094.
2.3. IBM System 360/OS and 370 Operating Systems (1960s, 1970s)
Not only was IBM firmly into the computer business by
the early 1960s, but IBM had many competitors since numerous large and
small companies had discovered there was money to be made in computing
machinery. Unfortunately, computer manufacturers had developed a
divided product line, with one set of computers for business (e.g.,
tabulating, inventory, payroll, etc.) and another collection of
machines for scientific work (e.g., matrix inversion, solution of
differential equations). The scientific machines had high-performance
arithmetic logic units (ALUs), whereas business machines were better
suited to processing large amounts of data using integer arithmetic.
Maintenance of two separate but incompatible product
lines was prohibitively expensive. Also, manufacturers did not
usually support customers who initially bought a small computer then
wanted to move their programs to a bigger machine. Instead, the users
had to rewrite all their programs to work on the larger machine. Both
of these practices (called application incompatibility and
version incompatibility) were terribly inefficient and
contributed to the relatively slow adoption of computers by
medium-sized businesses.
Definition. A multi-purpose computer can perform many different types of computations, for example, business and scientific applications.Definition. An upward compatible software and hardware paradigm ensures that a program written for a smaller (or earlier) machine in a product line will run on a larger (subsquently-developed) computer in the same product line.
In the early 1960s, IBM proposed to solve such
problems with one family of computers that were to be multi-purpose
and have upward compatibility (i.e., a user could in principle run his
program on any model). This revolutionary concept was instantiated in
the System/360 series of computers, which ranged from small business
computers to large scientific machines (eventually embracing a
primitive type of parallel, multiprocessor computer). The computing
hardware varied only in price, features, and performance, and was
amenable to either business or scientific computing needs. The 360
was the first computer to use transistors in small groups, which were
forerunners of the integrated circuit (introduced by Fairchild
Electronics in 1968). The idea of a family of software-compatible
machines was quickly adopted by all the major computer manufacturers.
System/360 machines were so well designed and ruggedly built that many
of them are still in use today, mainly in countries outside the United
States.
Unfortunately, System/360 attempted to be all things
to all users, and its OS thus developed into millions of lines of
assembly code that was difficult to maintain, enhance, or customize
for application-specific needs. Not only did the OS have to run well
on all different types of machines and for different programs, but it
had to be efficient for each of these applications. Although
noble in concept, the System/360 OS (unsurprisingly called OS/360) was
constantly being modified to suit customer demands and accomodate new
features. These new releases introduced further bugs. In response to
customer complaints arising from the effects of these bugs, IBM
produced a steady stream of software patches designed to
correct a given bug (often, without much regard for other effects of
the patch). Since the patches were hastily written, new bugs were
often introduced in addition to the undesireable side effects of each
new system release or patch.
Given its size, complexity, and problems, it is a
wonder that OS/360 survived as long as it did (in the mainstream of
American computing, until the mid 1970s). The IBM System 370 family
of computers capitalized on the new technology of large-scale
integration, and took IBM's large-scale operating system strategies
well into the late 1970s, when several new lines of machines (4300 and
3090 series) were developed, the latter of which persists to the
present day.
Despite its shortcomings, OS/360 satisfied most of
IBM's customers, produced vast amounts of revenue for IBM, and
introduced a revolutionary new concept called multiprogramming.
OS/370 greatly extended the functionality of OS/360 and continued to
grow into a ever-larger body of software that facilitated enhanced
efficiency, multiprogramming, virtual memory, file sharing and
computer security, etc. We next discuss the key innovation of
multiprogramming.
2.3.1. Multiprogramming
- Definition.Multiprogramming involves having more
than one job in memory at a given time.
Recall our discussion of early operating systems in
Section 2.2. For example, when the main computer was loading a job
from its input tape or was loading a compiled program from scratch
tape, the CPU and arithmetic unit sat idle. Following the same line
of reasoning as in the development of the first operating systems,
computer designers produced an operating system concept that could
make better utilization of the CPU while I/O functions were being
performed by the remainder of the machine. This was especially
important in business computing, where 80 to 90 percent of the tasks
in a given program are typically I/O operations.
Multiprogramming provided a solution to the idle CPU
problem by casting computation in terms of a process cycle,
which has the following process states:
Load: A given process P is loaded into memory from secondary storage such as tape or disk.Run: All or a part of P executes, producing intermediate or final results.Wait (or Block:) The execution of P is suspended and P is loaded onto a wait queue, which is a job queue in memory where waiting jobs are temporarily stored (similar to being put on hold during a telephone conversation).Resume: P is taken out of the wait queue and resumes its execution on the CPU exactly where it left off when it was put into the wait queue (also called the wait state).End: Execution of P terminates (normally or abnormally) and the results of P are written to an output device. The memory occupied by P is cleared for another process.
Implementationally, memory was partitioned into
several pieces, each of which had a different job. While one job was
running on the CPU, another might be using the I/O processor to output
results. This virtually ensured that the CPU was utilized nearly all
the time. Special hardware and software was required to protect each
job from having its memory overwritten or read by other jobs, but
these problems were worked out in later versions of OS/360.
Definition. Spooling (an acronym for Simultaneous Peripheral Operation On Line) involves concurrent loading of a process from input into memory.
Another technological development that made computers
more efficient was the introduction of magnetic disks as storage
media. Originally the size of a washing machine and storing a
whopping 10MB of data, disks were seen as a way to eliminate the
costly overhead (as well as mistakes) associated with human operators
who had to carry and mount/demount magnetic tapes on prespecified tape
drives. The availability of disk storage led to the obsolescence of
batch queues by allowing a program to be transferred directly to
system disk while it was being read in from the card reader. This
application of spooling at the input, and the simultaneous
introduction of spooling for printers, further increased computing
efficiency by reducing the need for operators to mount tapes.
Similarly, the need for separate computers to handle the assembly of
job queues from cards to tape also disappeared, further reducing the
cost of computing. This meant that less time could be allocated to
each job, thereby increasing response time.
2.3.2. Time Sharing
The economic benefits of faster response time,
together with the development of faster CPUs and individual computer
terminals that had near-real-time response, introduced the possibility
of a variation on multiprogramming that allowed multiple users to
access a given machine. This practice, called time sharing is
based upon the following principle. Each user program or task is
divided into partitions of fixed length in time or fixed memory size.
For example, let two programs P1 and
P2 be divided into slices P1(1),
P1(2), ..., P1(N1), and
P2(1), P2(2), ..., P2(N2).
Given a fast CPU, a time-sharing system can interleave the process
segments so that P1 and P2 have alternate access
to the CPU, for example:
P1(1),P2(1),P1(2),P2(2),...
until the shorter of the two processes completes. It
is easy to see how this could be combined with the I/O blocking
strategy in multiprogramming (Section 2.3.1) to yield a highly
efficient computer system that gives the illusion of multiple
concurrent processes.
The chief problem with time sharing is the underlying
assumption that only a few of the users will be demanding CPU
resources at any given time. If many users demand CPU resources, then
the distance between each segment of a given program or process
increases (e.g., time between P1(1) and P1(2) in
the preceding example), and CPU delays can become prohibitive. A
solution to this problem, called parallel processing, employs a
multiprocessor computer to run each user program or segment of a
program on one or more processors, thereby achieving true concurrency.
This approach will be discussed briefly in Section 2.4.
Another problem with time-sharing is the assumption
that most interactive users will request jobs with short runtimes,
such as syntax debugging or compilation of a 600-line program, versus
sorting of a 10-billion record database. As a result, when the users
of a time-sharing system all request large jobs, the system bogs down.
The first realistic time-sharing system was CTSS,
developed at MIT on a customized IBM 7094 [2]. This project was
undertaken with the best of intentions, but did not become practical
until memory protection hardware was included later in the third
generation of computer hardware development.
However, the success of CTSS on the modified 7094
motivated development of a next-generation time-sharing system, called
MULTICS (from Multiplexed Information and Computing Service) a
general-purpose computer operating system developed by the Computer
System Research group at M. I. T. Project MAC, in cooperation with
Honeywell information Systems (formerly the General Electric Company
Computer Department) and the Bell Telephone Laboratories. This system
was designed to be a "computer utility", where users could request
computer services on an as-needed basis, within a primitive
interactive environment. MULTICS was implemented initially on the
Honeywell 645 computer system, an enhanced relative of the Honeywell
635 computer. MULTICS was then ported to (implemented on) a variety of
Honeywell machines, including the Honeywell 6180 computer system. It
embodied many capabilities substantially in advance of those provided
by other operating systems, particularly in the areas of security,
continuous operation, virtual memory, shareability of programs and
data, reliability and control. It also allowed different programming
and human interfaces to co-exist within a single system.
In summary, the revolutionary concepts that MULTICS
attempted to implement [3,4] were:
Security: A program could have its code or data stored in memory made invisible (and inaccessible) to other programs being run by the same user or by other users. This led to the development of modern computer security systems that protect executable and data partitions from unauthorized intrusion.Continuous Operation: Instead of being started or restarted every time a new batch or job was run, a machine supporting MULTICS would run continuously, similar to an electric generating plant (electric utility) providing power service to its customers. This idea has been extended in subsequent development to include fault tolerance, where a computer keeps running even if certain key components fail or are swapped out.Virtual Memory: Prior to MULTICS, computer memory was confined to physical memory, i.e., the memory that was physically installed in the machine. Thus, if a computer had 256KB of memory (a large machine, at that time!), then it could only hold 256KB of programs and data in its memory. MULTICS introduced an implementation of paging programs and data from memory to disk and back. For example, if a program was not running in memory, valuable memory could be freed up by writing the memory partition (page) in which the program was stored to disk, then using that page for another program. When the original program was needed again (e.g., taken out of wait state), it would be paged back from disk into memory and executed. This allowed a slower disk unit to serve as a sort of extended (or virtual) memory, while all the work was still done in the computer's physical memory. This technique is commonplace today, and is even used in some personal computers.Shareability of Programs and Data: Before MULTICS, each computer programmer or user had his or her own data and programs, usually stored on one or more magnetic tapes. There was no way to share data with other users online, other than to fill out a signed permission slip (piece of paper) that authorized the computer operator to mount your data tape for another user to access. This was time-consuming and unreliable. MULTICS exploited the relatively new technology of magnetic disks to make data or programs stored on one user's disk readable to other users, without computer operator intervention. This in part motivated the collaborative culture of computing that we know and enjoy today. MULTICS also provided a primitive type of data security mechanism that allowed a user to specify which other users could read his data. This was the beginning of computer security at the user level.Reliability and Control: Prior to MULTICS, software ran rather haphazardly on computers, and there was little in the way of reliable commercial products. For example, in my FORTRAN class in 1971, we ran small card decks on an IBM 360/44 (scientific machine), and when an erroneous job control card was read in, the entire machine would crash, along with all programs running on that machine. MULTICS attempted (not too successfully) to remedy this situation by introducing a strategy for crash detection and process rollback that could be thought of as forming the foundation for robust client-server systems today. Also, MULTICS attempted to place more control of the computing process in the user's hands, by automating functions that had previously been the domain of computer operators. MULTICS also tried to support multiple user interfaces, including (in its later years) text and primitive line-drawing graphics, which was a revolutionary concept at the time.
Although MULTICS introduced many important new ideas
into the computer literature, building a reliable MULTICS
implementation was much more difficult than anyone had anticipated.
General Electric dropped out early on and sold its computer division
to Honeywell, and Bell Labs dropped out later in the effort. MULTICS
implementations eventually were developed than ran more or less
reliably, but were installed at only a few dozen sites.
2.3.3. Minicomputers and UNIX
Part of the reason for the slow adoption of MULTICS
was the emergence of the minicomputer, a scaled-down
single-user version of a mainframe machine. Digital Equipment
Corporation (DEC) introduced the PDP-1 in 1961, which had only 4K of
18-bit words. However, at less than 1/20 the price of a 7094, the
PDP-1 sold well. A series of PDP models (all incompatible) followed,
culminating in the PDP-11, which was workhorse machine at many
laboratories well into the 1980s.
A computer scientist at Bell Labs by the name of Ken
Thompson, who had been on the MULTICS project, developed a single-user
version of MULTICS for the PDP-7. This was called UNiplexed
Information and Computing Service (UNICS), which name was quickly
changed to UNIXTM. Bell Labs then supported its
implementation on a PDP-11. Dennis Ritchie then worked with Thompson
to rewrite UNIX in a new, high-level language called "C", and Bell
Labs licensed the result to universities for a very small fee.
The availability of UNIX source code (at that time, a
revolutionary development) led to many improvements and variations.
The best-known version was developed at University of California at
Berkeley, and was called the Berkeley Software Distribution
(UNIX/BSD). This version featured improvements such as virtual
memory, a faster file system, TCP/IP support and sockets (for network
communication), etc. AT&T Bell Labs also developed a version called
UNIX System V, and various commercial workstation vendors have their
own versions (e.g., Sun Solaris, HP UNIX, Digital UNIX, SGI IRIX, and
IBM AIX), which have largely been derived from UNIX/BSD or System V.
UNIX has formed the basis for many operating systems,
whose improvements in recent years still originate in UNIX-based
systems. The UNIX system call interface and implementation has been
borrowed somewhat by most operating systems developed in the last 25
years.
2.4. Concurrency and Parallelism
Digressing briefly until we resume the discussion of
personal computer operating systems in Section 2.5, we note that
multiprogramming and time sharing led naturally to the issue of
concurrency. That is, if segments of different programs could be run
adjacent in time and interleaved so that users were deceived into
believing that a computer was running all their programs at the same
time, why couldn't this be done using multiple processors?
Definition. Concurrent processing involves computing different parts of processes or programs at the same time.
For example, given processes P1,
P2, ..., PN with average runtime T seconds,
instead of interleaving them to execute in slightly greater time than
N · T seconds, why not use N processors to have an average total
runtime slightly greater than T seconds? (Here, we say "slightly
greater than" because there is some operating system overhead in both
the sequential and parallel cases.)
This technique of using multiple processors
concurrently is called parallel processing, and has led to many
advances in computer science in the late 1980s and 1990s. Briefly
stated, parallel processing operates on the assumption that "many
hands make less work". Parallel algorithms have been discovered that
can sort N data in order log(N) time using order N processors.
Similar algorithms have been employed to drastically reduce the
computation time of large matrix operations that were previously
infeasible on sequential machines.
Parallel programming is quite difficult, since one
has the added problems of concurrent control of execution, security,
and reliability in a perspective of space and time. (In sequential
computers, time is the primary variable, and there is no real
concurrency.) As a result, one has a multi-variable optimization
problem that is difficult to solve in the static case (no fluctuations
in parameters). In the dynamic case (i.e, fluctuating system
parameters), this problem is extremely difficult, and is usually
solved only by approximation techniques.
Due to the difficulty of parallel programming, we
will not in this course cover computers or operating systems related
to this technique in high-performance dedicated machines. Instead, we
will concentrate on operating systems for sequential machines and
workstations that are connected to networks (e.g., an office network
of personal computers). We note in passing that network operating
systems (e.g., Linda and MVL) have been developed that use a large
array of networked computers (e.g., in a large office buildings) to
support a type of parallel distributed processing. These
systems are currently topics of keen research interest but have
encountered practical difficulties, not the least of which is getting
users' permission to have their computers taken over by a foreign host
when the users are away from their respective offices.
2.5. Impact of Personal Computers on OS Technology
Third-generation computer technology was based on
integrated circuits that were relatively simple and used small-scale
integration (SSI, tens of transistors on a chip) or medium-scale
integration (MSI, hundreds of transistors per chip). The advent of
large-scale integrated circuits (LSI) with thousands of transistors
per square centimeter made possible the construction of smaller
minicomputers that became affordable for personal or hobby use. These
early computers were, in a sense, throwbacks to early
plugboard-programmable devices. They did not have operating systems
as such, and were usually programmed in machine code using front-panel
toggle switches. Although fun for electronics hobbyists, it was
difficult to get useful work done with such machines.
2.5.1. Emergence of PC Operating Systems
In the mid-1970s, the Altair computer dominated the
personal market, and the IBM-PC was yet to be built. A young man from
a suburb of Seattle and his high-school friend decided to try
constructing a simple operating system and some user-friendly
utilities for the Altair and other personal computers. Their company,
Microsoft, experimented with UNIX by making its interface more like
the DEC VAX operating system (VMS). By combining concepts of UNIX and
VMS, Bill Gates was able to produce a simple operating system called
MS-DOS (MicroSoft Disk Operating System) that could be used on a few
personal machines. Early version of MS-DOS were developed for very
small computers and thus had to run in very small memory partitions
(approximately 16KB at the outset). MS-DOS was copied or adapted by a
variety of companies, including Tandy, which issued TRS-DOS for their
TRS line of PCs.
In 1980, IBM released the IBM-PC (personal computer),
which happened also to be their first computing product not to be
designated by a number (as opposed to the 1401, 7094, 360, 370, 4300,
3060, 3090, ad nauseam). Microsoft was a key player in the release of
the PC, having extended MS-DOS to run on the Intel 8086 (and the
follow-on 8088) processor. For many years after its initial release,
MS-DOS still lacked features of mainframe operating systems, such as
security, virtual memory, concurrency, multiprogramming, etc. MS-DOS
was (and remains) a text-only operating system and thus did not
support the graphics displays and protocols that later emerged from
Apple Computer Company's development of the Lisa and Macintosh
machines (Section 2.5.2).
Other personal computer operating systems of note in
the early 1980s included CP/M and VM, which were developed for a broad
range of systems, but did not survive the competition with Microsoft
in the IBM-PC arena and are basically footnotes in the history of OS
development. A number of idiosyncratic PCs, notably the Osborne and
Kaypro, which sold large numbers of units initially, were equipped
with CP/M. Kaypro later converted to MS-DOS and sold IBM-PC
compatible computers.
2.5.2. Apple and Macintosh/OS, with a Taste of Linux
The Apple computer company was selling their Apple II
machines at a brisk pace when the IBM-PC was introduced in 1980.
Apple II platforms ran Apple-DOS, a text-based OS with graphics
capabilities and a simple programming language (BASIC) that was
developed in part by Microsoft.
As the IBM-PC emerged from the shadows, Apple was
putting the finishing touches on their prototype graphics-based
machine called Lisa. The Lisa machine was an unfortunately clumsy and
rather slow (not to mention expensive) computer that was based on
research performed at Xerox Palo Alto Research Center (Xerox PARC) in
the 1970s on graphical user interfaces (GUIs) and hypertext.
Fortunately, Apple very quickly remedied the Lisa's defects and
produced the Macintosh (or Mac), which was the first graphics-based
personal computer. Macs were easier to use than IBM-PC's and posed a
challenge to IBM's growing domination of the PC market. Macintosh
computers initially used the Motorola 68k series of processors, and
have lately embraced the PowerPC chip, developed by a consortium of
computer manufacturers. In contrast, Microsoft has largely stuck with
the Intel line of 80x86 chips, which has dominated the PC marketplace.
The Macintosh operating system, called MacOS,
provided a fully functional graphics interface and was more complete
and significantly easier to use than MS-DOS. MacOS did not have all
the features of UNIX, but provided substantial graphics support, a
sophisticated file system, and early support for networking and
virtual memory systems. It is interesting to note that, as of January
2000, Apple remains Microsoft's sole viable competitor in the
alternative PC operating system market, and is now partially owned by
Microsoft.
Another PC-based operating system, called Linux, is a
public-domain version of UNIX that runs on Intel platforms and is
rapidly gaining acceptance among technically oriented computer users.
Unfortunately, Linux has proven less tractable for non-technical
people, who constitute the vast majority of computer users. As a
result, it is reasonable to suggest that Microsoft is likely to
dominate the PC OS market for the foreseeable future.
2.5.3. Mach
As operating systems develop, whether for personal
computers or mainframes, they tend to grow larger and more cumbersome.
Problems associated with this trend include increased errors,
difficulty in making the OS more reliable, and lack of adaptation to
new features. In response to these problems, Carnegie-Mellon
University researchers developed Mach in the mid- to late-1980s. Mach
is based on the idea of a central partition of the OS being active at
all times. This partition is called a microkernel. The
remainder of the usual operating system functionality is provided by
processes running outside the microkernel, which can be invoked on an
as-needed basis.
Mach provides processes for UNIX emulation, so UNIX
programs can be supported in addition to a wide variety of
Mach-compatible programs. Mach was used in the NeXt
machine, developed by Steve Jobs after he left Apple Computer in the
late 1980s. Although this machine was ultimately unsuccessful
commercially, it introduced many important new ideas in software
design and use, and capitalized upon the synergy between Mach and
UNIX.
A consortium of computer vendors has developed an
operating system called Open Systems Foundation 1 (OSF/1), which is
based on Mach. Additionally, the ideas developed in Mach have been
highly influential in operating system development since the late
1980s.
2.5.4. Microsoft Windows and NT
Recall that early IBM PCs used early version of
MS-DOS, which poorly supported graphics and had a text-only interface.
With the popularity of Macintosh computers with their more
sophisticated MacOS operating system, Microsoft felt commercial
pressure to develop the Windows operating system. Initially designed
as a sort of graphical interface for MS-DOS, and built directly upon
MS-DOS (with all its inherent deficiencies), MS-Windows went through
several revisions before including more standard OS functionality and
becoming commercially attractive. MS-Windows 3.1 was the first
commercially successful version, and introduced the important concept
of interoperability to PCs.
Definition. Interoperability means that a given application can be run on many different computers (hardware platforms) or operating systems (software platforms).
Interoperability was a key buzzword at Microsoft for
several years, and remains a keystone of the company's aggressive,
commercially successful plan to unify business and home computing
environments worldwide. In short MS-Windows can (in principle) run on
a variety of processors. Additionally, other companies (such as
Citrix) have constructed software emulators that give the user the
look-and-feel of MS-Windows on machines for which Windows is not
natively available (e.g., Sun workstations). These OS
emulators allow Windows-compatible software to run in nearly the
same mode that it runs on Windows-compatible machines, and thus extend
interoperability to further unify computing practice.
MS-Windows adds so much functionality to MS-DOS that
it could itself be thought of as an operating system. However, MS-DOS
deficiencies became obvious as PCs gained more power and flexibility.
In particular, MS-DOS was developed for a small PC with small memory,
no hard disk, no protection, no memory management, and no network (all
capabilities taken for granted today). Although later versions of
MS-DOS addressed these problems, the OS has severe drawbacks that
render it obsolete in a network-intensive environment. Unfortunately,
MS-Windows also suffers from these problems, since it is built on
MS-DOS.
As a result, Microsoft was motivated to develop a
modern operating system for PCs, which it called Windows/New
Technology (Windows/NT). This system was first released in 1993, and
incorporates many features of UNIX and Mach. In later sections of
these notes, NT and UNIX will be compared and contrasted. Suffice to
say that NT is now the choice of most network administrators for a
Microsoft-compatible networking environment. However, it is
interesting to note that Microsoft, for all its promotion of the
Windows family of OS products, still sells UNIX under the trade name
of XENIX.
Data Structures: Introductory Material
Computer program design can be made much easier by organizing information into abstract data structures (ADS) or abstract data types (ADTs). For example, one can model a table of numbers that has three columns and an indeterminate number of rows, in terms of an array with two dimensions: (1) a large number of rows, and (2) three columns.A key feature of modern computer programs is the ability to manipulate ADS using procedures or methods that are predefined by the programmer or software designer. This requires that data structures be specified carefully, with forethought, and in detail.This section is organized as follows:1.1. Introduction and Overview
1.2. Review of Discrete Math Concepts and Notation
1.3. Overview of Java Programming Language
1.4. Overview of Complexity Notation
1.5. Recursive Computation
1.6. Arrays and Lists
1.7. Searching, Selection, and SortingIn this class, we will concentrate only on data structures called arrays, lists, stacks, queues, heaps, graphs, and trees. In order to address the topics and algorithms covered in this class, we present each data structure in terms of a unifying formalism, namely, the ADT and its associated operations, called the ADT sequence.We then discuss discrete math concepts and notation, and present an overview of the Java programming language, which is the language of choice for this class. This will help you establish background proficiency in theory and programming languages required for successful completion of the projects.Complexity analysis is an important tool of the algorithm designer, which we discuss in sufficient detail to permit analysis of the algorithms presented in this class. We also discuss the use of recursion and the complexity analysis technique of recursion relations. Recursion is an important component of many modern software systems, programs, and modules. We will see that the design of recursive programs is somewhat different from the linear, sequential flow of control that you have become accustomed to in beginning-level programming. Recursion relations are thus required to analyze this different method of programming in a way that is decidedly different from analysis of algorithms with linear, sequential flow.Arrays and lists are simple data structures that facilitate a wide variety of operations on ADTs, and thus form the basis for modern algorithm and software design and implementation. In order to find data stored in arrays or lists we perform an operation called searching. When this process is associated with order statistics (e.g., finding the median of a sequence), this is sometimes called selection. In order to facilitate efficient searching, we need to be able to sort the numbers or strings (sequence of characters) over which we want to search. In the case of real numbers, sorting means that the numbers are arranged in order of increasing magnitude.1.1. Introduction and Overview
In order to set the proper context for this class, which is concerned with low-level mechanisms that facilitate good software design, we begin with a discussion of software design and engineering principles.1.1.1. Software Design & Engineering Goals
Software design can be divided into two levels. High-level software design and analysis seeks to produce correct, efficient software. At a low level, we are more concerned with robustness, adaptability, and reusability.1.1.1.1. High-level Software Design Goals. In order to produce programs that work as specified for all instances of input, the following design goals must be achieved at a high level:Correctness -- a data structure or algorithm is designed, at a high level, to work as specified for all possible inputs.
Example. A sorting algorithm must arrange its inputs in ascending or descending order only.Efficiency implies (a) fast runtime, and (b) minimal use of computational resources.
Example. Algorithm design for real-time systems is not just a matter of using fast hardware. One must produce fast algorithms that can take advantage of commercial off-the-shelf (COTS) hardware, for decreased production cost.1.1.1.2. Low-level Software Design Goals. Correctly designed and functioning programs must achieve the following goals within an implementational perspective:Robustness -- a program produces correct outputs for all inputs on any hardware platform on which the program is implemented. Robustness includes the concept of scalability -- the capability of a data structure or algorithm to handle expanding input size without incurring prohibitive complexity or causing inaccuracy or failure.
Adaptability -- software must be able to be modified or evolved over time to meet environmental changes (e.g., increased CPU speed, client-server implementation, or new functionality to increase market demand).
Example. The Year 2000 Problem is an excellent example of poor software design, where date fields in old software (also called legacy code) were not designed to be large enough to accomodate date codes for an interval greater than 100 years.Reusability -- a given partition or piece of code must be able to be used as a component in different systems or in different application domains without significant modification.
Example. Upgrades to existing software systems should be simple to design and implement, but often aren't, due to idiosyncratic and poorly engineered programming.To meet the above-listed goals, object-oriented programming evolved from procedural and functional programming.
1.1.1.3. Object-Oriented Design Principles help a programmer or software designer to organize the structure and functionality of code or programs according to several guiding principles, which include:
- Abstraction -- One must be able to distill a complicated system into a simple, concise, clear description of system structure and functionality.
Example. The "Cut and Paste" operations on a word processor's Edit Menu are simple, elegant, and intuitively obvious, but may be implementationally complex.Observation. Applying the principle of abstraction to data structures produces Abstract Data Types (ADTs).Definition. An ADT is a mathematical model of a data structure that specifies (a) type of data stored and (b) operations on the stored data, with specification of the types of parameters in the operations. In particular, an ADT specifies what each operation does, but not necessarily how a given operation works.Example. In Java, an ADT is modelled as an interface implemented as a class. Classes specify how a given operation on the ADT's data is to be performed.Definition. A Java class implements an interface if and only if the class methods include those of the interface. Note that a given class can implement multiple interfaces.- Encapsulation -- different components of a software system should implement an abstraction without revealing internal details of the implementation. This is called information hiding.
Example. An Edit menu on a word processor is completely useful without the user knowing how the Cut and Paste processes work.Advantages of encapsulation include:
Loose coupling between classes -- programmer only needs to meet interface specification, not worry about the details of a given method's functionality.
Adaptability -- code can be changed without adversely afecting program functionality, due to the presence of a uniform interface.- Modularity -- the presence of an organizing structure that partitions sfotware systems into functional units based on hierarchical relationships.
Example. Two kinds of hierarchical relationships include the has-a and is-a relations. The has-a relation induces component hierarchies such as the one shown in Figure 1. Here, the door, window, wall, and floor are constituents of a building. The is-a relation induces membership hierarchies such as the one shown in Figure 2, where a residential or commercial structure are both instances of a more general type of structure called a building.
Grouping of common functionality at the most general level.
Viewing specialized behavior and attributes as extensions of one or more general cases, also called inheritance.1.1.1.4. Object-Oriented Design Techniques. In order to implement object-oriented design paradigms, the following techniques have been developed and are available in most object-oriented languages such as C++ and Java:We examine each of these concepts in detail, as follows.Classes and Objects -- the actors in the object-oriented programming (OOP) paradigm, which have methods that are the actions performed by the objects. Classes and objects facilitate abstraction and, hence, robustness.
Interfaces and Strong Typing facilitate efficient interpretation or compilation of the source language, without confusing ambiguities. This facilitates encapsulation and, hence, adaptability.
Inheritance and Polymorphism allow a given object or subclass to specialize the attributes or capabilities of the parent class. For example, in Figure 2, a skyscraper specializes the description of an office building. Polymorphism refers to the ability of a given operation or method to admit different types of operands that are specializations of a higher-level class description. Inheritance and polymorphism faciliate modularity and reusability when class descriptions are available to designers and programmers.
Definition. Objects are actors in the OOP paradigm.
Definition. A class is a specification of data fieldsinstance variables that a class contains, as well as those operations that a class can execute.
Concept of Reference: When an object is created, the OOP interpreter or compiler (1) allocates memory for the given object, and (2) binds a variable to the object, where the variable is said to reference the object.
Interaction. A class or method can either (a) execute one of an object's methods or (b) look up the fields of an object.
Observation. In OOP, objects interact with message passing. For example, two objects o1 and o2 can interact by o1 requesting o2 to:
- Print a description of itself,
- Convert o2 to a string representation, or
- Return the value of one of o2's data fields.
Alternatively, o1 can access o2's fields directly, but only if o2 has given o1 permission for such access. This is an example of information hiding.- Interfaces and Strong Typing.
Observation. Each class must slecify the Application Programming Interface (API) that it presents to other objects. The ADT approach is to specify the interface as a class type definition and collection of methods for that type, where all arguments for each method must have specific types.
Remark. Tight type specifications (strong typing) are rigidly enforced by the interpreter or compiler, which requires rigorous type matching at runtime.Note: This encapsulation is achieved at the cost of work to the programmer.
- Inheritance and Polymorphism.
Observation. Inheritance involves design of high-level classes that can be specialized to more particular class descriptions.
Example. The Java class Number can be specialized to float, integer, double, or long.
Definition. A base class or superclass is the most general class.
Observation. Specialized classes or derived classes inherit base properties or methods from the general class, which are specialized for a given subclass. Figure 3 illustrates this concept for the general class of Animal, which can include subclasses of dog, horse, and human, among others.
Example. A reference variable v reference an object o, but must define which class C to which it is allowed to refer.If Class D extends Class C (which it does in Figure 3), then v can refer to any class D.When o refers to an object from Class D, it will execute the method o.bark(), o.neigh(), o.talk(), or o.sing(), as appropriate. In this case, D is said to override method b() from Class C.When o references an object in Class D, it will execute the method o.make-noise(), since the object-oriented interpreter or compiler searches from the most specific to most general class. Thus, o can be polymorphic.Observation. This kind of functional organization allows a specialized class D to:
- Extend a class (e.g., C in Figure 3),
- Inherit generic methods from C, and
- redefine other methods from C to account for specific properties of objects in D.
Remark. The method that processes the message to invoke a given method, then finds that method, is called the dynamic dispatch algorithm.Definition. A method's signature is the combination of the method-name together with the type and number of arguments passed to the method.Implementation. Java provides a watered-down kind of polymorphism called overloading, where even one class D can have multiple methods with the same name, provided that each method has a different signature.Observation. Inheritance, polymorphism, and method overloading support reusability.1.1.2. Abstract Data Structures and ADTs
The purpose of an abstract data structure (ADS) is to narrow the semantic gap between the user's programming constructs or application software and the computing hardware (otherwise known as the bare machine).When instances of a given ADS can be constructed from a higher-level description (e.g., a Java class definition), then we say that such instances have a given Abstract Data Type (e.g., array, list, stack, ...) In this class we will study several ADTs, but they will each have a common set of generic operations, which are discussed as follows.1.1.3. The ADT Sequence
There is a more-or-less common set of operations that can be performed on each ADT, which we list as follows. Here a given ADT is assumed (e.g., the current class), a value in an ADT element is denoted by x, and the position of an ADT element in a multi-element ADT is denoted by "i".
IsFull() returnsTrueif the ADT cannot contain any more data, andFalseotherwise.
IsEmpty() returnsTrueif the ADT contains no data, andFalseotherwise.
Size() returns an integer greater than or equal to zero, which denotes the number of elements in the ADT.
PositionOf(x) returns an integer or coordinate that denotes the position of the first instance of x encountered while searching through the elements of the ADT in a prespecified scanning order.
ValueAt(i) returns the value of the i-th element in the ADT.
InsertValue(x,i) inserts the value x into the ADT via the following steps:
- Create a new element of type compatible with the ADT.
- Place the value x in the new element.
ReplaceValueAt(i,x) puts the value x in the i-th element of the ADT without disturbing the order of elements in the ADT.
DeleteElement(i) removes the i-th element of the ADT, restoring the ADT's order property. This essentially reverses the order of steps used in the InsertValue operation.
OutputADT usually writes the ADT to disk, either as an object in the native programming language (e.g., Java object serialization), or as an ASCII string representation.Note that all of the preceding methods might not be used with a given ADT. For example, an array does not facilitate easy insertion or deletion of its elements, but a list does.1.1.4. Representing ADTs in a Programming Language
In Java, which is the language of choice for this class, we represent each ADT as a class. In earlier languages like FORTRAN, there were a fixed number of datatypes, which could not be altered. In PASCAL, one could predefine datatypes, but there were limitations on what kind of data the datatypes could hold. This definition process is made more flexible in C, and the encapsulation of class definitions and methods unified the earlier distinctions of "data" and "procedure" in terms of objects.It is worth noting that certain languages before PASCAL had very flexible but idiosyncratic datatype definitions. SNOBOL, an early string processing language, had a very flexible ADT definition system and a powerful pattern-matching language that could be customized (albeit with some effort) to find data stored in ADTs. PL/1 made some feeble attempts at more flexible datatype definitions, but was too large a language to be of practical use, and died an unmourned death after several revisions.1.2. Review of Discrete Math Concepts and Notation
This review is given in Appendix A, and is thus not reproduced here.1.3. Overview of Java Programming Language
A thorough review of Java, with tutorials, is organized in hierarchical form in Appendix B, and is thus not reproduced here. Also, Dr. Crummer's Java tutorial is a good place to get started programming in Java. Additional textbooks and references are cited in this link.1.4. Overview of Complexity Notation
In this section, we discuss some concepts of complexity, including Big-Oh notation.Concept. It is useful to be able to specify the complexity of a function or algorithm, i.e., how its computational cost varies with input size.
Background and Application. Complexity analysis is key to the design of efficient algorithms. Note that the work or storage (memory) requirement of a given algorithm can vary with the architecture (processor) that the algorithm runs on, as well as the type of software that is being used (e.g., runtime modules generated from a FORTRAN versus C++ compiler). Thus, complexity analysis tends to be an approximate science, and will be so presented in this sub-section.
In particular, when we analyze the complexity of an algorithm, we are interested in establishing bounds on work, space, or time needed to execute the computation specified by the algorithm. Hence, we will begin our exposition of complexity analysis by analyzing the upper bound on the growth of a function.
Representation. "Big-Oh Notation" (e.g., O(x2) reads Big-Oh of x-squared) is used to specify the upper bound on the complexity of a function f. The bound is specified in terms of another function g and two constraints, C and k.
Definition. Let f,g : R -> R be functions. We say that f(x) = O(g(x)) if there exist constants C,kR such that
| f(x) |whenever x > k.C · | g(x) | ,
Example. Let f = x3 + 3x2. If C = 2, then| f(x) | = | x3 + 3x2 |whenever x > 2. The constants C,k = 2 fulfill the preceding definition, and f(x) = O(g(x)).In the next section, we will discuss composition of big-Oh estimates, to determine an upper bound on the complexity of composite functions and algorithms.1.4.1. Algorithms and Algorithmic Complexity
We begin by noting that, in this section, we use algorithms to introduce salient concepts and to concentrate on analysis of algorithm performance, especially computational complexity.Definition. An algorithm is a finite set of instruction for performing a computation or solving a problem.
Types of Algorithms Considered. In this course, we will concentrate on several different types of relatively simple algorithms, namely:
Selection -- Finding a value in a list, counting numbers;Sorting -- Arranging numbers in order of increasing or decreasing value; andComparison -- Matching a test pattern with patterns in a database .Properties of Algorithms. It is useful for an algorithm to have the following properties:
Input -- Values that are accepted by the algorithm are called input or arguments.
Output -- The result produced by the algorithm is the solution to the problem that the algorithm is designed to address.
Definiteness -- The steps in a given algorithm must be well defined.
Correctness -- The algorithm must perform the task it is designed to perform, for all input combinations.
Finiteness -- Output is produced by the algorithm after a finite number of computational steps.
Effectiveness -- Each step of the algorithm must be performed exactly, in finite time.
Generality -- The procedure inherent in a specific algorithm should be applicable to all algorithms of the same general form, with minor modifications permitted.Concept. In order to facilitate the design of efficient algorithms, it is necessary to estimate the bounds on complexity of candidate algorithms.
Representation. Complexity is typically represented via the following measures, which are numbered in the order that they are typically computed by a system designer:
Work W(n) -- How many operations of each given type are required for an algorithm to produce specified output given n inputs?
Space S(n) -- How much storage (memory or disk) is required for an algorithm to produce specified output given n inputs?
Time T(n) -- How long does it take to compute the algorithm (with n inputs) on a given architecture?
Cost C(n) = T(n) · S(n) -- Sometimes called the space-time bandwidth product, this measure tells a system designer what expenditure of aggregate computational resources is required to compute a given algorithm with n inputs.Procedure. Analysis of algorithmic complexity generally proceeds as follows:
Step 1. Decompose the algorithm into steps and operations.
Step 2. For each step or operation, determine the desired complexity measures, typically using Big-Oh notation, or other types of complexity bounds discussed below.
Step 3. Compose the component measures obtained in Step 2 via theorems presented below, to obtain the complexity estimate(s) for the entire algorithm.Example. Consider the following procedure for finding the maximum of a sequence of numbers. An assessment of the work requirement is given to the right of each statement.
Let {an} = (a1,a2,...,an) { max = a1 # One I/O operation for i = 2 to n do: # Loop iterates n-1 times { if aimax then # One comparison per iteration max := ai } # Maybe one I/O operation }
Analysis. (1) In the preceding algorithm, we note that there are n-1 comparisons within the loop. (2) In a randomly ordered sequence, half the values will be less than the mean, and a1 would be assumed to have the mean value (for purposes of analysis). Hence, there will be an average of n/2 I/O operations to replace the valuemaxwith ai. Thus, there are n/2 + 1 I/O operations. (3)This means that the preceding algorithm is O(n) in comparisons and I/O operations. More precisely, we assert that, in the average case:
W(n) = n-1 comparisons + (n/2 - 1) I/O operations.Exercise. In the worst case, there would be n I/O operations. Why is this so? Hint: This may be a quiz or exam question.
Useful Terms. When we discuss algorithms, we often use the following terms:
Tractable -- An algorithm belongs to class P, such that the algorithm is solvable in polynomial time (hence the use of P for polynomial). This means that complexity of the algorithm is O(nd), where d may be large (which typically implies slow execution).
Intractable -- The algorithm in question requires greater than polynomial work, time, space, or cost. Approximate solutions to such algorithms are often more efficient than exact solutions, and are preferred in such cases.
Solvable -- An algorithm exists that generates a solution to the problem addressed by the algorithm, but the algorithm is not necessarily tractable.
Unsolvable -- No algorithm exists for solving the given problem. Example: Turing showed that it is impossible to decide whether or not a program will terminate on a given input.
Class NP -- If a problem is in Class NP (non-polynomial), then no algorithm with polynomial worst-case complexity can solve this problem.
Class NP-Complete -- If any problem is in Class NP-Complete, then any polynomial-time algorithm that could be used to solve this problem could solve all NP-complete problems. Also, it is generally accepted, but not proven, that no NP-complete problem can be solved in polynomial time.1.4.2. Big-Oh Notation and Associated Identities.
We have previously defined Big-Oh notation. In this section, we present identities for Big-Oh notation that allow the computation of complexity estimates for composite functions, with examples.Theorem 1. (Polynomial Dominance) If f(x) =anxn , then f(x) = O(xn).
Example. Find the Big-Oh complexity estimate for n!
Observe that n! = 1 · 2 · 3 · ... · n
Hence, n! = O(nn) .Theorem 2. (Additive Combination) If f1(x) = O(g1(x)) and f2(x) = O(g2(x)), then(f1 + f2)(x) = O(max(g1(x), g2(x)) .Theorem 3. (Multiplicative Combination) If f1(x) = O(g1(x)) and f2(x) = O(g2(x)), then(f1 · f2)(x) = O(g1(x) · g2(x)) .Example. Estimate the complexity of f(n) = 3n · log(n!).
Step 1. From the previous example, log(n!) is O(n · log(n)) .
Step 2. Let f1 = 3n and f2 = log(n!), with f = f1 · f2 .
Step 3. Note that 3n = O(n).
Step 4. From the law of multiplicative combination of complexity estimates (as shown in Theorem 3, above), it follows thatg1(x) · g2(x) = O(n) · O(n · n log(n)) = O(n2 · log(n)) .1.4.3. Big-Omega and Big-Theta Notation.
Big-Oh notation establishes an upper bound on an algorithm's complexity, since | f(x) |Concept. To establish a lower bound on complexity, we use(called Big-Omega) and
(called Big-Theta) notation.
Definition. If f,g : R -> R are functions andC,k
| f(x) |then f(x) is said to be
Example. If f(x) = 8x3 + 5x2 + 7, then f(x) isx
Definition. If f,g : R -> R are functions, where (a) f(x) is O(g(x)) and (b) f(x) is
Note: When Big-Theta notation is used, then g(x) is usually a simple function (e.g., n, nm, log n).1.5. Recursive Computation
It is often useful to write functions, procedures, or methods that call themselves. This technique, called recursion, is employed extensively in computer science, particularly in the solution of problems involving graphs or trees. In this section, we discuss the impact of recursive procedures on computational cost, with examples.Concept. A recursive procedure calls itself. Thus, in a sequence of n procedure calls, the output of the n-th procedure becomes the input of the (n-1)-th procedure, which becomes the input of the (n-2)-th procedure, and so forth, until the top-level procedure is reached. This procedure processes the output of the 2nd procedure call in the recursive sequence, and returns a net result.
Example. Let a function f(x) compute the expression:fi(x) = fi-1(x) + x , i = 1..n .which simply computes x + x + ... + x as many times as there are values in i (in this example, n times).
Observation. If a procedure that has computational work requirement W (exclusive of the function call overhead) calls itself n times, then that procedure incurs a cost of nW operations, plus the additional overhead of n-1 function calls. Note: The first function call would occur whether the procedure was iterative or was called recursively.
Remark. The overhead of additional function calls is one of the significant disadvantages of recursive programming. An additional disadvantage is the effort involved in writing a recursive version of an iterative procedure. The following example is illustrative.
Example. Observe the following two code fragments, each of which computes x factorial, where x is a positive integer:
NONRECURSIVE RECURSIVE factorial(x : int) factorial(x : int): { fact = 1 { return(x * factorial(x-1)) for i = 2 to n } fact = fact * i endfor return(fact) }Observe that the nonrecursive or iterative algorithm is more verbose than the recursive formulation. Both compute x!, and both require n-1 multiplications to do so. However, the nonrecursive algorithm has an overhead of n-1 loop index incrementations, whereas the recursive algorithm requires n-1 additional function calls, as discussed previously.
Example. Observe the following two code fragments, each of which computes the sum of a sequence a of n elements.
NONRECURSIVE RECURSIVE sum(a : array [1..n] of int) sum(a : array [1..n] of int, i,n : int) { sum = 0 { if i = 1 for i = 1 to n then return(a[1]) sum = sum + a[i] else if i > 1 and i <= n endfor then return(a[i] + sum(a[i+1],i+1,n) return(sum) } }As before, note that the nonrecursive or iterative algorithm has more lines of code than the recursive formulation. Both compute sum(a), and both require n-1 additions to do so. However, the nonrecursive algorithm has an overhead of n-1 loop index incrementations, whereas the recursive algorithm requires 2(n-1) incrementations of index i, together with n-1 additional function calls, as discussed previously. This means that a recursive algorithm would probably not be the best way of computing a vector sum.
Observation. In most computing systems, the overhead of function calls far exceeds the work requirement of incrementing a loop index. Thus, the recursive formulation is usually (but not always) more expensive. In practice, the nonrecursive procedure is more expensive if computation of the index i, or some other index derived from i, takes extensively many arithmetic operations, which taken in aggregate would be more expensive than the additional function calls of the recursive computation. However, the recursive formulation has the advantage of being concise, and of being able to portray the kind of function calls that mathematicians often like to write with much less effort than iterative formulations of the same function.Hence, recursive functions are likely to remain useful for some time in the future. Applications of recursive function calls abound, for example, in compilers, parsing of formal and natural language text, and in algorithms that are based on data structures called graphs or trees.1.6. Arrays and Lists.
We begin with several observations about the use of arrays in computer programs.Observation. In the early days of computer programming, machines were dedicated to the task of computing tables of artillery trajectories (WWII) and tables of accounting and business inventory information (early 1950s). Thus, numerically intensive computing machines were designed to handle linear or two-dimensional arrays. When computer programming became better established and scientific applications came into vogue, the FORTRAN (FORmula TRANslation) language was developed which supported multiply-dimensioned arrays.
Definition. An array is a data structure whose domain is a finite subset of Euclidean n-space Rn.
Observation. Arrays are customarily assigned the datatype of the elements that they contain, which can be one and only one datatype. For example, arrays can be integer-, real-, string-, or character-valued, but elements of more than one such type are not usually contained in an array.
Example. The vector a = (2,3,-1,5,6,0,9,-7) is a one-dimensional integer-valued array. The first value, denoted by a(1), equals 2. The i-th value in the array is denoted by a(i), i = 1..8, because there are eight elements in the array.
Example. The two-dimensional array shown below has four columns and three rows. Each element of the array is referenced by its (row,column) coordinate. For example, the element whose value equals 9.2 is in row 3, column 4, which we write as a(3,4) = 9.2 .
Figure 1.6.1. An example of a two-dimensional array.Remark. The use of row-column indices or coordinates makes referencing elements of arrays convenient. It is especially useful to note that arrays can be indexed in loops. For example, a loop that would set all the elements of the array a in Figure 1.6.1 to zero could be written in pseudocode as:: DECLARE a : array [3,4] of real; : FOR i = 1 to 3 DO: FOR j = 1 to 4 DO: a(i,j) := 0.0 ENDFOR ENDFORObservation. In the above pseudocode fragment, each dimension of the array a has a lower and upper limit to the subscripts that are allowed. One finds the size of each dimension by subtracting the lower limit from the upper limit, then adding one.
Example. If an array is dimensioned as:b : array [-2..3,5..9,4..8] of integer;then the number of elements in the array is computed as follows:STEP 1: Dimension #1 is of size (3 - -2 + 1) = 6 STEP 2: Dimension #2 is of size (9 - 5 + 1) = 5 STEP 3: Dimension #3 is of size (8 - 4 + 1) = 5 STEP 4: Multiply the dimension sizes: Nelements = 6 x 5 x 5 = 150to find that there are 150 elements in the array.
In the early days of computing, it was very important to know how large arrays were, because computer memory was extremely limited. Today, with large memory models, one still must be careful not to specify array dimensions too large, but it is less of a problem than in the past.
Programming Hint: As we mentioned in class, one always initializes program variables to which file data is not assigned prior to computing a given expression. One can use the preceding loop structure to assign initial values to array elements in an efficient manner.A key problem with arrays is that they have fixed size. Hence, they are called static data structures. We will soon examine techniques for programming data structures called lists, which can expand and contract with the data that one puts into or takes out of the list. Another problem of arrays which we mentioned previously is that they are statically typed, i.e., cannot be used to store any type of data, but only the type of data assigned to them in the declaration statement in which they were specified. It is interesting to note that certain languages, such as SNOBOL and ICON, have circumvented this difficulty by providing a TABLE data structure that can hold data of any type. You are not responsible for knowing about the TABLE data structure, however, since it is not available in Java, or in most modern high-level programming languages.We next consider the case of singly- and doubly-linked linear lists.Concept. We have seen that arrays use an index to point to each element of the array. For example, given an array element a[i], i = 1..n, the third element of the array, denoted by 3, would be specified as a[3] if n = 3 or greater. Another type of linear data structure, similar in concept but not in implementation to a one-dimensional array, is the list.
Definition. A list is an ordered collection of elements, where each element has at least one pointer and at least one value.
Definition. A singly-linked list (SLL) is a list where each element has the following fields:
Value: The value that is stored in the list element. This can be of any datatype, including a list. Lists can thus be multi-dimensional, i.e., a list element can point to another list through its value field.Next-pointer: This is a pointer to the next element in the list, if it exists, and has datatype list-element.Convention. Given an SLL element called this, we usually reference the element's value and next-pointer as this.value and this.next, respectively.
Observation. As shown in the schematic diagram of an SLL in Figure 1.6.2, there are different ways to construct list representations. Two are shown - the top example has sentinel head and tail nodes, which represent extra storage and maintenance overhead, but can provide a measure of data security if head and tail manipulation operations are employed. The simplified list representation, without sentinel head or tail nodes, is more common. In this case, the first node is the head, and the last node (the one that points to the null value) is the tail of the list.
Figure 1.6.2. Schematic diagram of Singly-Linked List, where L[i], i=1..n, denotes a value in the i-th list element.Definition. A doubly-linked list (DLL) is a list where each element has the following fields:
Value: The value that is stored in the list element. This can be of any datatype, including a list. Lists can thus be multi-dimensional, i.e., a list element can point to another list through its value field.
Next-pointer: This is a pointer to the next element in the list, if it exists, and has datatype list-element.
Prev-pointer: This is a pointer to the previous element in the list, if it exists, and has datatype list-element.
Convention. Given an DLL element called this, we usually reference the element's value, next-pointer, and prev-pointer as this.value, this.next, and this.prev, respectively.Observation. Finding the head and tail of a DLL is a little easier than with an SLL, since the prev-pointer (next-pointer) of the DLL's head (tail) points to the null value.Figure 1.6.3. Schematic diagram of Doubly-Linked List, where L[i], i=1..n, denotes a value in the i-th list element.Observation. Traversing a DLL is easier than traversing an SLL because the prev-pointer of the DLL allows one to backtrack (i.e., traverse the list backwards). This is important in certain types of sorting or searching operations conducted over lists. SLLs have the advantage of being slightly simpler than DLLs, and are easier to implement, since they have 2/3 the data fields of a DLL.ADT Operations. An SLL or DLL has the following ADT operations:Size(): Returns the number of elements in the list.
IsEmpty(): Returns true if the list has no elements.
i-th(i): Returns the value of the i-th element in the list. This function is sometimes called ElementAt(i).
Head(): Returns the value of the first element in the list.
Tail(): Returns the value of the last element in the list.
Insert(x,i): Inserts a new element in the list, after the i-th element, where the new element has value x. The (i+1)-th and following elements each have their indices incremented. That is, the (i+1)-th element becomes the (i+2)-th element, and so forth.
Delete(i): Deletes the i-th element from the list. The (i+1)-th and following elements each have their indices decremented. That is, the (i+1)-th element becomes the i-th element, and so forth.
Observation. The i-th or ElementAt operation incurs O(n) complexity for an n-element SLL or DLL. Thus, if you put the ElementAt operation inside a loop having m iterations, this will incur a work requirement of O(n2) operations.
Figure 1.6.4. Schematic diagram of inserting an element with value "C" in a Doubly-Linked List, between elements with value "A" and "B". Note that Steps 1-3 generalize insertion in an SLL, if and only if the list nodes are SLL nodes, as shown in Figure 1.6.2.Figure 1.6.5. Result of insertion operation in DLL. Steps from Figure 1.6.4 are numbered in blue.Complexity. The work of inserting an element in a DLL, as shown in Figure 1.6.4, is (a) one list element creation plus (b) four list pointer assignments. For an SLL, this work is reduced by two pointer assignments, since the prev-element pointer is not available for use in an SLL. The preceding work estimate does not include the work required to find the list.1.7. Searching, Selection, and Sorting
In computer science, we are often called upon to perform practical tasks, such as looking up an entry in a table or dictionary, finding items in a database, etc. The process of searching for such items is also called selection, since one attempts to select a given value from an array, list, set, or other ADT. Selection is discussed in Section 1.7.1.Another important task in computer science is ordering a list of names, numbers, or other data according to a prespecified ordering scheme. This process, called sorting, has been extensively investigated and was the subject of much research in the 1950s through 1970s. Thus, there are many sorting algorithms of interest. We will study several of these in Section 1.7.2.1.7.1. Selection
There are two types of selection algorithms of interest in this introductory class. First, we have the simple technique of linear search, which merely scans each item of a data structure to see if its value corresponds to a prespecified or reference value. This requires O(n) work for searching through n data. Second, one can produce hierarchical arrangements of data, called trees, for which search algorithms exist that can find data in O(log n) work.Concept. Linear search scans through a list, array, or other ADT, comparing the value of each element to a reference value. At the first match, the search algorithm returns the position of the value of interest.
Analysis. The best case for a linear search algorithm is to have the value x for which one is searching located at the first position of the ADT. This obviously requires a constant number of comparison operations, i.e., the work is O(1) comparison. In the worst case, x is located at the n-th position of the ADT, for which the associated work is O(n).
Algorithm. Given an n-element vector a, linear search for an element x can be implemented as follows:LinSearch(x,a,n): { for i = 1 to n if (a[i] = x) then return(i) }Analysis. The preceding algorithm incurs a minimum (maximum) of 1 (n) comparisons, for an average work requirement of (n+1)/2 comparisons.
Example. Given a five-element vector a = (2,8,32,7,4), let us search for the element a[i] = 7, i = 1..5. The following table suffices to exemplify linear search:STEP i VALUE a[i] CHECK RESULT NEXT i ---- ------- ---- --------- -------- -------- 1 1 2 a[1] = 7? 2!= 7 2 2 2 8 a[2] = 7? 8!= 7 3 3 3 32 a[3] = 7? 32!= 7 3 4 4 7 a[2] = 7? 7 = 7 stopObservation. Search trees are usually binary, that is, there are two children per internal node. This allows one to use a binary relation such as greater-than or less-than to construct a min-tree or max-tree that has, at the root of the tree, the minimum or maximum of the data stored in the tree. We state a more general case, as follows.
Definition. An n-ary search tree is a rooted tree that has n children per nonterminal node.
Definition. In an n-ary search tree of depth L levels, O(L) operations are required to find a prespecified value stored in one of the tree nodes. Given m data items stored in a complete n-ary search tree, the number of levels is computed as follows:L = ceil(lognm) ,where ceil denotes the ceiling function.Observation. The disadvantage of some types of search trees, such as binary search trees, is that the sequence stored in the tree must be presorted in order to have the order property required to implement O(log n) work in the selection process. However, other types of search trees, such as some implementations of binary search trees, AVL trees, and red-black trees discussed in Section 3, require only O(log n) work to insert and delete an element from the tree.1.7.2. Sorting
There are several types of sorting algorithms of interest to this course. First, we have the simple technique of injection-sort, which positions each input value in its position on the number line, using the value as an index for the sorted array. A more sophisticated sorting technique, called histogram-sort or bin-sort scans the histogram of a sequence to output the values stored in the histogram in a predetermined order. Since the domain of the histogram is assumed to be an n-element subset of the integers or reals, the work involved is O(n) additions and I/O operations.More sophisticated sorting algorithms were developed to handle large input sequences that had arbitrary values. For example, bubble-sort migrates the maximum or minimum of a sequence to the head of the sequence. The remainder of the sequence is then sorted in the same way. This means that there are n passes, where the i-th pass requires scanning through i data. This involves O(n2) comparison and I/O operations, and is thus prohibitive for very large sequences. The more intelligent (and efficient) technique of insertion-sort selectively positions each value of an input sequence in its proper position in the sequence, according to a prespecified order. This can be thought of as a type of intelligent bubble-sort algorithm, and requires far fewer operations than bubble-sort.Still more efficient sorting algorithms include merge-sort and quick-sort, which are tree-structured. These algorithms, which belong to the general class of divide-and-conquer algorithms, first split (divide) an input sequence into subsequences, which are then sorted when a given subsequence has two elements. (Note that sequences that have one element do not need to be sorted.) The subsequences are then recombined to yield a sorted sequence. Merge-sort partitions the input sequence based on its length, which is assumed to be a power of two, since a binary tree is employed. Quick-sort partitions an input sequence based on a pivot value that is computed from the values in the sequence. Quick-sort is therefore said to be data-dependent.1.7.1.1. Injection Sort.
Concept. Given an input sequence [an] that is a subset of the integers modulo n, injection-sort places each value a(i) in its proper place on the number line.Figure 1.7.1. Schematic diagram of injection sort applied to input vector (2,4,3,1) to yield sorted vector (1,2,3,4).Algorithm. Assume that a sequence a has n distinct integers taken from the set Zn, where n is small (i.e., less than 1M). We can sort a as follows:InjectionSort(a : array [1..n] of integer modulo n): { for i = 1 to n do: b[a[i]] = a[i] endfor return(b) }Analysis. The preceding algorithm consists of one loop, which has n iterations and performs work of two memory I/O operations during each iteration. Thus, the total work is 2n memory I/O operations, and the injection-sort algorithm sorts its input with O(n) work.Injection sort has no best or worst case input, because the same process is applied to each input, regardless of how the input is ordered. Another way of saying this is to observe that there are no decision statements in the algorithm, and thus no way of exiting the loop before completion. We say that such an algorithm has performance or complexity that is not data-dependent.1.7.1.2. Histogram Sort (Bin Sort).
Concept. Given an input sequence [an] whose values can be mapped to the integers modulo m, where m > n is possible, histogram-sort (also called bin-sort) places each value a(i) in its proper place on the number line by scanning the histogram of a.Figure 1.7.2. Schematic diagram of histogram sort applied to input vector (2,1,4,2,3,1,4,1) to yield sorted vector (1,1,1,2,2,3,4,4).Algorithm. Assume that a sequence a has n distinct elements that can be mapped to the set Zm, where m is small. We can sort a using its histogram h(a), as follows:HistogramSort(a : array [1..n] of integer modulo n): { h = 0 # Zero the histogram buffer for i = 1 to n do: # Build the histogram h[a[i]]++ endfor i = 0 # Zero the output counter for j = 1 to m do: # Histogram domain scan loop for k = 1 to h[j] do: # Bin countup loop i++ b[i] = j # Put bin index in output endfor endfor return(b) }Analysis. The preceding algorithm consists of two loops. The first loop has n iterations and performs work of one memory I/O operation and one incrementation during each iteration. The second loop is a compound loop (j and k are indices) that iterates a total n times, since there are n data in the histogram (recall that there were n input data). For each iteration of the second loop, there is one incrementation (i++) and one memory I/O operation. Thus, the total work is 2n memory I/O operations and incrementations, and the histogram-sort algorithm sorts its input with O(n) work.For the same reasons given in Section 1.7.1.1, Analysis, Histogram-Sort has no best case or worst case, and is not data-dependent. However, like Injection-Sort, Histogram-Sort requires a highly restricted input, which is not necessarily a realistic constraint.Remark. Because a histogram is said to consist of bins in which the count for a given value is stored (like putting n beans in bin x if the value x occurs n times), histogram-sort is often called bin-sort.We next move from the O(n) complexity sorting algorithms with restricted input sets to an early sorting algorithm with unrestricted real input values.1.7.1.3. Bubble Sort.
Concept. Given an input sequence [an] whose values are assumed to be real numbers, bubble-sort places each value a(i) in its proper place on the number line by respectively "bubbling up" or migrating the minimum (maximum) of the sequence or remaining subsequence to achieve a sort in ascending (descending) order.Figure 1.7.3. Schematic diagram of bubble sort applied to input vector (2,1,4,2,3) to yield sorted vector (1,2,2,3,4). Note that the bounded regions are the areas to which bubble-sort is applied. Each of these areas decreases by one element, and is equal in size to n-i, where i denotes the index of the processing step.Algorithm. Assume that a sequence a has n real elements, which need not be distinct. We can sort a in ascending order using bubble-sort, as follows:
BubbleSort(a,n): { read(a[i], i = 1..n) for i = 1 to n do: min = minimum of the sequence a[i..n] pos = position at which the minimum occurred b[i] = min swap(a[i],a[pos]) endfor return(b) }Analysis. The preceding algorithm consists of one loop, which has n iterations and performs work of (n-i+1) comparisons per iteration. Thus the complexity is O(n) comparisons, which dominate over the memory I/O operations.In the best case, the input is presorted and bubble-sort requires a minimum number of I/O operations. (Hint: The exact number of I/O operations might be a good exam question.)In the worst case, the input is sorted opposite to the desired order of the sorted output, and a maximum number of I/O operations are required. The number of comparisons is invariant to input value, since the maximum of each sequence or subsequence is not known a priori.1.7.1.4. Insertion Sort.
Concept. Given an input sequence [an] whose values are assumed to be numbers, insertion-sort places each value a(i) in its proper place in the sorted sequence by "bubbling up" or migrating the minimum (maximum) of the sequence or remaining subsequence, only if that value is out of order.Figure 1.7.4. Schematic diagram of insertion sort applied to input vector (2,1,4,2,3) to yield sorted vector (1,2,2,3,4). Note that a given exchange terminates with determination of InPlace ordering, regardless of how many steps are in the exchange. Also, when the marker is at the final position (in this case, the fifth position because n = 5), this signals the final exchange.Algorithm. Assume that a sequence a has n elements, which need not be distinct. We can sort a in ascending order using insertion-sort, as follows:InsertionSort(a,n): { for i = 2 to n do: if a[i] is out of place in the subsequence a[1..i], then migrate a[i] upward until it is in its proper place endif endfor return(a) }Analysis. The preceding algorithm consists of one loop, which has n iterations and performs a maximum of O(n) comparisons per iteration. This occurs when the input sequence is sorted in opposite order from the desired output (worst case). In the best case, the input sequence is properly sorted, and a total of n-1 comparisons are required (because the previous subsequence is already sorted). Thus, the complexity of insertion-sort varies from O(n) to O(n2) comparisons, which dominate over the memory I/O operations. For this reason, the InsertionSort algorithm has data-dependent complexity.1.7.1.5. Merge Sort.
Concept. Given an input sequence [an] whose values are assumed to be numbers, and n is a power of 2 for convenience, merge-sort uses divide-and-conquer to sort the input recursively until there are subsequences of two elements only. These are sorted using one comparison and one swap operation (if required), then are merged into progressively larger subsequences, until the input length is attained. The result is a sorted sequence. As shown in Figure 1.7.5, the MergeSort algorithm consists of (1) splitting, (2) sorting, and (3) merging steps. For purposes of clarity, we assume that MergeSort input consists of distinct integers.Figure 1.7.5. Schematic diagram of merge sort applied to input vector (2,8,5,3,7,1,6,4) to yield sorted vector (1,2,3,4,5,6,7,8).Algorithm. Assume that a sequence a has n elements, which need not be distinct. We can sort a in ascending order using merge-sort, as follows:Merge(L1,L2): { L3 = empty list repeat until list L1 or list L2 is empty: if head(L1) < head(L2) then insert head(L1) at the head of L3 delete(head(L1)) else insert head(L2) at the head of L3 delete(head(L2)) endif end-repeat concatenate the remaining (non-empty) list onto the rear of L3 } MergeSort(a,n): { if size(a) = 1 then return(a) elseif size(a) = 2 then if a[1] and a[2] are not in proper order, then swap(a[1],a[2]) endif else { split a into two lists of equal size, L and R return(Merge(MergeSort(L,n/2),MergeSort(R,n/2))) } endif }Merge Example. The merging algorithm's operation may not be intuitively obvious, so we present the following example, in which two 2-element sorted sequences from Figure 1.7.5 are merged.Thus, one can see that merging in ascending (descending) order is merely a matter of outputting the smaller (larger) of the list heads, then deleting that element from its respective list. Since the lists L1 and L2 are already sorted, this is possible. If L1 and L2 were not in-order, Merge would not work.Remark. Another way to think of merging is to imagine a process by which two decks of n cards, each of which is sorted, could be shuffled to yield one sorted deck.Analysis. The preceding algorithm MergeSort calls itself recursively log(n)-1 times. This leads to the construction of a recursion tree of log(n) levels. The swap operation adds another level to the tree, and the resultant Merge operations unwind the recursion stack to yield another log(n) levels.
1.7.1.6. Quick Sort.
Quick-sort is conceptually similar to merge-sort, but can improve slightly upon merge-sort's performance by eliminating the merging phase. This holds mainly when the input can be divided in the same way as merge-sort's input (i.e., halving of each sequence or subsequence at each level of the tree).Concept. Given an input sequence [an] whose values are assumed to be numbers, and n is arbitrary, quick-sort uses divide-and-conquer to sort the input recursively until there are subsequences of one or two elements only. These are sorted using one comparison and one swap operation (if required), then are concatenated into progressively larger subsequences, until the input length is attained. The result is a sorted sequence. The difference between merge-sort and quick-sort is that quick-sort uses a pivot value instead of the sequence or subsequence size to decide how to partition the input.Figure 1.7.6. Schematic diagram of quick sort applied to input vector (42,43,2,1,46,4,45) to yield sorted vector (1,2,4,42,43,45,46).Algorithm. Assume that a sequence a has n elements, which need not be distinct. We can sort a in ascending order using quick-sort, as follows:QuickSort(a): { if size(a) = 1 then return(a) elseif size(a) = 2 then if a[1] and a[2] are not in proper order, then swap(a[1],a[2]) endif else { pick a pivot value p based on the values of a split a into two lists, L and R, where { L contains the values of a that are less than p R contains the remaining values of a } return(Concatenate(QuickSort(L),QuickSort(R))) } endif }Analysis. The preceding algorithm calls itself recursively a minimum of ceil(log(n))-1 times, and a maximum of n-1 times (worst case). This leads to the construction of a recursion tree having log(n) to n-1 levels. The swap operation adds another level to the tree, and the resultant concatenation operations unwind the recursion stack to yield another log(n) to n levels.The sorting phase requires n/2 comparisons and a maximum of n I/O operations, if 2-element subsequences result (best case) and each 2-element subsequence is unsorted. The concatenation phase unwinds the recursion stack, and requires no comparisons, unlike merge-sort. Since there are log(n) to n-1 levels in the concatenation portion of the sorting architecture, and each level has n I/O operations, a total of O(n log(n)) to O(n2) I/O operations are required. This means that the quick-sort algorithm requires O(n log(n)) to O(n2) work, depending on how the pivot value is chosen. If the median is chosen as the pivot, then quick-sort can actually be slightly faster than merge-sort, since there are no comparisons involved in the conquer phase.The best-case input is a sequence that has all subsequences produced by splitting with the same mean as their median, since this produces the fewest number of levels. The worst-case input for splitting on the mean is a geometric series sorted in opposite order to the desired sorting order, for example, (10,100,1000,...). When the mean is taken, such a sequence will require n-1 levels of splitting and n-1 levels of concatenation, because it will be split into n-2 subsequences of one element each, and one subsequence of two elements.Note: Students should verify this by constructing a splitting and concatenation diagram for the sequence S = (101,102,...,108).In Section 2, we examine data structures such as sets and strings that can be represented by lists, then look at a special data structure called a heap. It will be shown that a sorting algorithm based on the heap (unsurprisingly called HeapSort) can achieve O(n log(n)) complexity and is easier to implement than MergeSort.
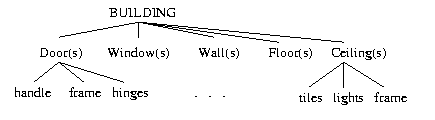

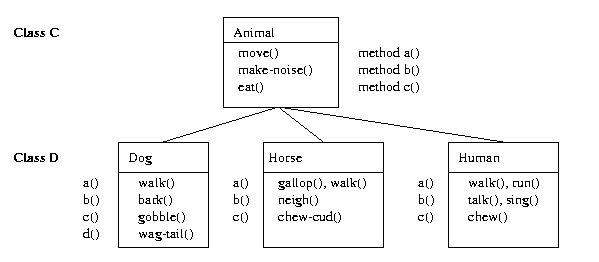
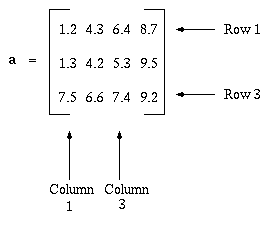
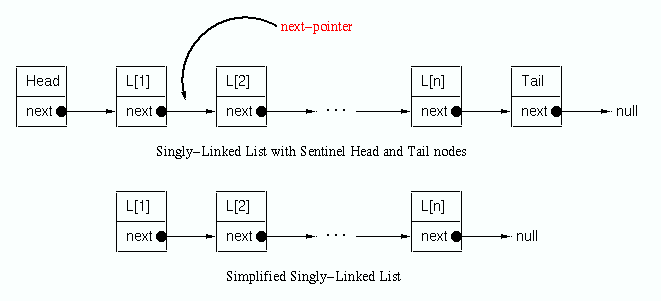
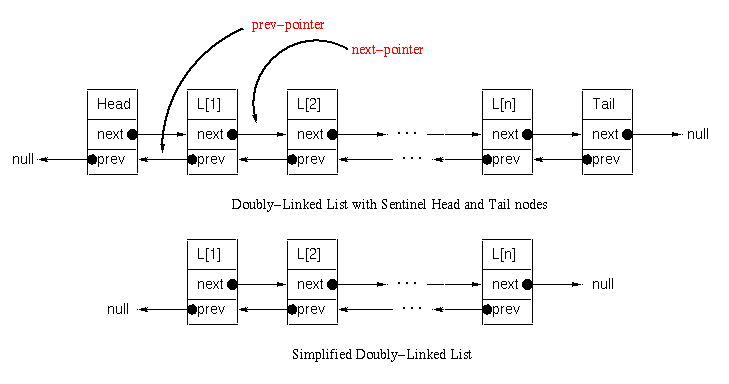
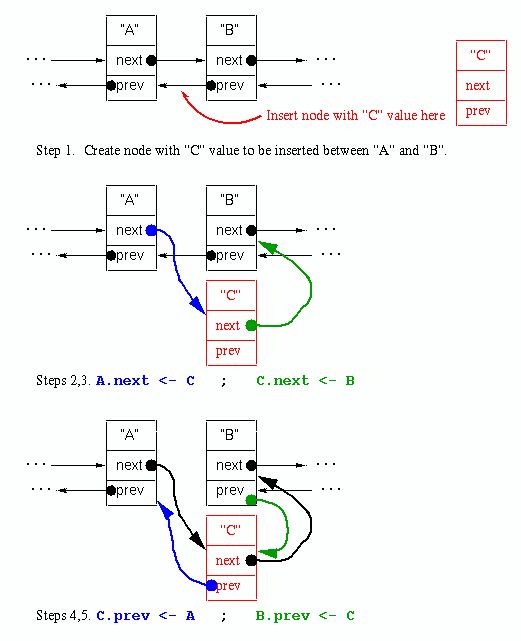
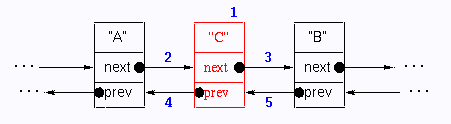
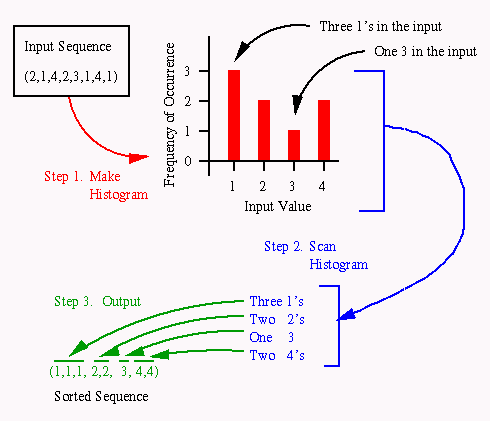
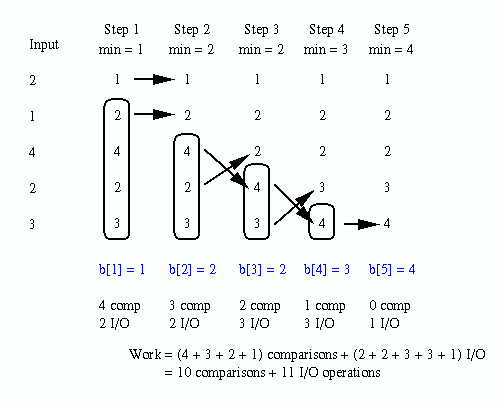
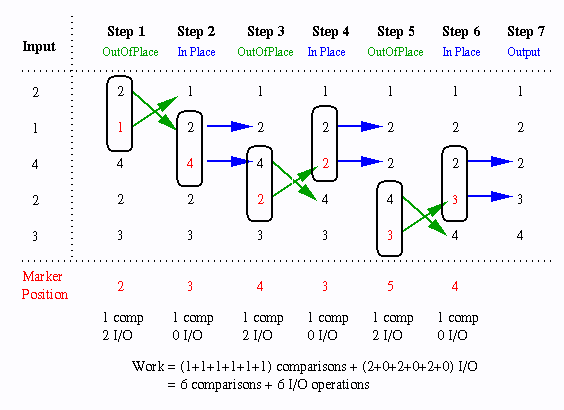
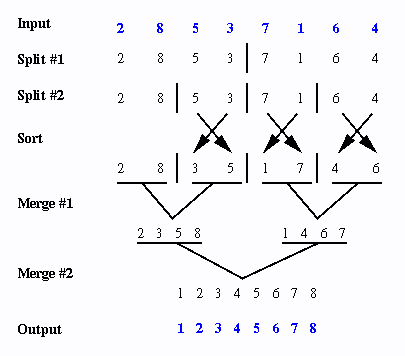

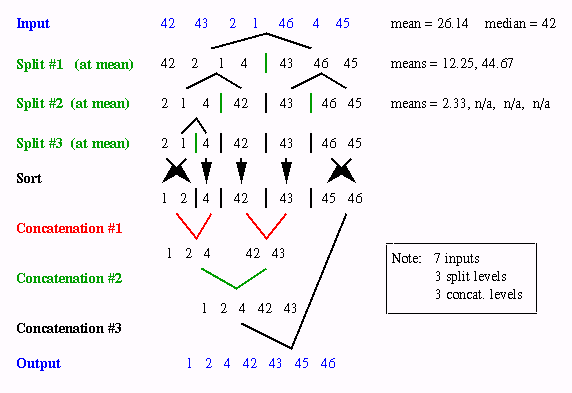
Subscribe to:
Posts (Atom)