1. Given the relations
employee (name, salary, deptno) and
department (deptno, deptname, address)
Which of the following queries cannot be expressed using the basic relational algebra
operations (U, -, x, , p)? (GATE CS 2000)
, p)? (GATE CS 2000)
(a) Department address of every employee
(b) Employees whose name is the same as their department name
(c) The sum of all employees’ salaries
(d) All employees of a given department
Answer: (c)
Explanation:
The six basic operators of relational algebra are the selection( ), the projection(
), the projection( ),
the Cartesian product (x) (also called the cross product or cross
join), the set union (U), the set difference (-), and the rename (p).
These six operators are fundamental in the sense that none of them can
be omitted without losing expressive power. Many other operators have
been defined in terms of these six. Among the most important are set
intersection, division, and the natural join, but aggregation is not
possible with these basic relational algebra operations. So, we cannot
run sum of all employees’ salaries with the six operations.
),
the Cartesian product (x) (also called the cross product or cross
join), the set union (U), the set difference (-), and the rename (p).
These six operators are fundamental in the sense that none of them can
be omitted without losing expressive power. Many other operators have
been defined in terms of these six. Among the most important are set
intersection, division, and the natural join, but aggregation is not
possible with these basic relational algebra operations. So, we cannot
run sum of all employees’ salaries with the six operations.
References:
http://en.wikipedia.org/wiki/Relational_algebra
http://faculty.ksu.edu.sa/zitouni/203%20Haseb%20%20Lecture%20Notes/Relional%20Algebra.pdf
2. Given the following relation instance.
(a) XY -> Z and Z -> Y
(b) YZ -> X and Y -> Z
(c) YZ -> X and X -> Z
(d) XZ -> Y and Y -> X
Answer: (b)
Explanation:
A functional dependency (FD) is a constraint between two sets of attributes in a relation from a database. A FD X->Y require that the value of X uniquely determines the value of Y where X and Y are set of attributes. FD is a generalization of the notion of a key.
Given that X, Y, and Z are sets of attributes in a relation R, one can derive several properties of functional dependencies. Among the most important are Armstrong’s axioms, which are used in database normalization:
So, Y -> X and Y -> Z hold for above schema.
From rule of augmentation we can say YZ->X. If we understand the notion of FD, we don’t need to apply axioms to find out which option is true, just by looking at the schema and options we can say that (b) is true.
References:
http://www.cse.iitb.ac.in/~sudarsha/db-book/slide-dir/ch7.pdf
http://en.wikipedia.org/wiki/Functional_dependency
3. Given relations r(w, x) and s(y, z), the result of
select distinct w, x
from r, s
is guaranteed to be same as r, provided (GATE CS 2000)
(a) r has no duplicates and s is non-empty
(b) r and s have no duplicates
(c) s has no duplicates and r is non-empty
(d) r and s have the same number of tuples
Answer: (a)
Explanation:
The query selects all attributes of r. Since we have distinct in query, result can be equal to r only if r doesn’t have duplicates.
If we do not give any attribute on which we want to join two tables, then the queries like above become equivalent to Cartesian product. Cartisian product of two sets will be empty if any of the two sets is empty. So, s should have atleast one record to get all rows of r.
4. In SQL, relations can contain null values, and comparisons with null values are treated as unknown. Suppose all comparisons with a null value are treated as false. Which of the
following pairs is not equivalent? (GATE CS 2000)
(a) x = 5, not (not (x = 5)
(b) x = 5, x > 4 and x < 6, where x is an integer
(c) x < 5, not(x = 5)
(d) None of the above
Answer (c)
Explanation:
It doesn’t need much explanation. For all values smaller than 5, x < 5 will always be true but x = 5 will be false.
5. Consider a schema R(A, B, C, D) and functional dependencies A -> B and C -> D. Then the decomposition of R into R1 (A, B) and R2(C, D) is (GATE CS 2001)
a) dependency preserving and loss less join
b) loss less join but not dependency preserving
c) dependency preserving but not loss less join
d) not dependency preserving and not loss less join
Answer: (c)
Explanation:
Dependency Preserving Decomposition:
Decomposition of R into R1 and R2 is a dependency preserving decomposition if closure of functional dependencies after decomposition is same as closure of of FDs before decomposition.
A simple way is to just check whether we can derive all the original FDs from the FDs present after decomposition.
In the above question R(A, B, C, D) is decomposed into R1 (A, B) and R2(C, D) and there are only two FDs A -> B and C -> D. So, the decomposition is dependency preserving
Lossless-Join Decomposition:
Decomposition of R into R1 and R2 is a lossless-join decomposition if at least one of the following functional dependencies are in F+ (Closure of functional dependencies)
 R2 is empty. So, the decomposition is not lossless.
R2 is empty. So, the decomposition is not lossless.
References:
http://www.cs.sfu.ca/CC/354/han/materia/notes/354notes-chapter6/node1.html
6) Which of the following statements are TRUE about an SQL query?
P: An SQL query can contain a HAVING clause even if it does not a GROUP BY clause
Q: An SQL query can contain a HAVING clause only if it has a GROUP BY clause
R: All attributes used in the GROUP BY clause must appear in the SELECT clause
S: Not all attributes used in the GROUP BY clause need to apper in the SELECT clause
(A) P and R
(B) P and S
(C) Q and R
(D) Q and S
Answer (B)
P is correct. HAVING clause can also be used with aggregate function. If we use a HAVING clause without a GROUP BY clause, the HAVING condition applies to all rows that satisfy the search condition. In other words, all rows that satisfy the search condition make up a single group. See this for more details.
S is correct. To verify S, try following queries in SQL.
7) Given the basic ER and relational models, which of the following is INCORRECT?
(A) An attributes of an entity can have more that one value
(B) An attribute of an entity can be composite
(C) In a row of a relational table, an attribute can have more than one value
(D) In a row of a relational table, an attribute can have exactly one value or a NULL value
Answer (C)
The term ‘entity’ belongs to ER model and the term ‘relational table’ belongs to relational model.
A and B both are true. ER model supports both multivalued and composite attributes See this for more details.
(C) is false and (D) is true. In Relation model, an entry in relational table can can have exactly one value or a NULL.
8) Suppose (A, B) and (C,D) are two relation schemas. Let r1 and r2 be the corresponding relation instances. B is a foreign key that refers to C in r2. If data in r1 and r2 satisfy referential integrity constraints, which of the following is ALWAYS TRUE?

Answer (A)
B is a foreign key in r1 that refers to C in r2. r1 and r2 satisfy referential integrity constraints. So every value that exists in column B of r1 must also exist in column C of r2.
9) Which of the following is TRUE?
(A) Every relation in 2NF is also in BCNF
(B) A relation R is in 3NF if every non-prime attribute of R is fully functionally dependent on every key of R
(C) Every relation in BCNF is also in 3NF
(D) No relation can be in both BCNF and 3NF
Answer (C)
BCNF is a stronger version 3NF. So every relation in BCNF will also be in 3NF.
10) Consider the following transactions with data items P and Q initialized to zero:
(A) A serializable schedule
(B) A schedule that is not conflict serializable
(C) A conflict serializable schedule
(D) A schedule for which a precedence graph cannot be drawn
Answer (B)
Two or more actions are said to be in conflict if:
1) The actions belong to different transactions.
2) At least one of the actions is a write operation.
3) The actions access the same object (read or write).
The schedules S1 and S2 are said to be conflict-equivalent if the following conditions are satisfied:
1) Both schedules S1 and S2 involve the same set of transactions (including ordering of actions within each transaction).
2) The order of each pair of conflicting actions in S1 and S2 are the same.
A schedule is said to be conflict-serializable when the schedule is conflict-equivalent to one or more serial schedules.
Source: Wiki Page for Schedule
In the given scenario, there are two possible serial schedules:
1) T1 followed by T2
2) T2 followed by T1.
In both of the serial schedules, one of the transactions reads the value written by other transaction as a first step. Therefore, any non-serial interleaving of T1 and T2 will not be conflict serializable.
11) Consider the following relations A, B, C. How many tuples does the result of the following relational algebra expression contain? Assume that the schema of A U B is the same as that of A.

(B) 4
(C) 5
(D) 9
Answer (A)
12) Consider the above tables A, B and C. How many tuples does the result of the following SQL query contains?
(B) 3
(C) 0
(D) 1
Answer (B)
The meaning of “ALL” is the A.Age should be greater than all the values returned by the subquery. There is no entry with name “arun” in table B. So the subquery will return NULL. If a subquery returns NULL, then the condition becomes true for all rows of A (See this for details). So all rows of table A are selected.
13. Consider a relational table with a single record for each registered student with the following attributes.
1. Registration_Number:< Unique registration number for each registered student
2. UID: Unique Identity number, unique at the national level for each citizen
3. BankAccount_Number: Unique account number at the bank. A student can have multiple accounts or joint accounts. This attributes stores the primary account number
4. Name: Name of the Student
5. Hostel_Room: Room number of the hostel
Which of the following options is INCORRECT?
(A) BankAccount_Number is a candidate key
(B) Registration_Number can be a primary key
(C) UID is a candidate key if all students are from the same country
(D) If S is a superkey such that S UID is NULL then S  UID is also a superkey
UID is also a superkey
Answer (A)
A Candidate Key value must uniquely identify the corresponding row in table. BankAccount_Number is not a candidate key. As per the question “A student can have multiple accounts or joint accounts. This attributes stores the primary account number”. If two students have a joint account and if the joint account is their primary account, then BankAccount_Number value cannot uniquely identify a row.
14) Consider a relational table r with sufficient number of records, having attributes A1, A2,…, An and let 1 <= p <= n. Two queries Q1 and Q2 are given below.

The database can be configured to do ordered indexing on Ap or hashing on Ap. Which of the following statements is TRUE?
(A) Ordered indexing will always outperform hashing for both queries
(B) Hashing will always outperform ordered indexing for both queries
(C) Hashing will outperform ordered indexing on Q1, but not on Q2
(D) Hashing will outperform ordered indexing on Q2, but not on Q1.
Answer (C)
If record are accessed for a particular value from table, hashing will do better. If records are accessed in a range of values, ordered indexing will perform better. See this for more details.
15) Database table by name Loan_Records is given below.
(B) 9
(C) 5
(D) 6
Answer (C)
Following will be contents of temporary table S
16) the table at any point in time. Using MX and MY, new records are inserted in the table 128 times with X and Y values being MX+1, 2*MY+1 respectively. It may be noted that each time after the insertion, values of MX and MY change. What will be the output of the following SQL query after the steps mentioned above are carried out?
(B) 255
(C) 129
(D) 257
Answer (A)
Passenger (pid, pname, age)
Reservation (pid, class, tid)
Table: Passenger pid pname age ----------------- 0 Sachin 65 1 Rahul 66 2 Sourav 67 3 Anil 69 Table : Reservation pid class tid --------------- 0 AC 8200 1 AC 8201 2 SC 8201 5 AC 8203 1 SC 8204 3 AC 8202 What pids are returned by the following SQL query for the above instance of the tables?
SLECT pid FROM Reservation , WHERE class ‘AC’ AND EXISTS (SELECT * FROM Passenger WHERE age > 65 AND Passenger. pid = Reservation.pid) (A) 1, 0
(B) 1, 2
(C) 1, 3
(S) 1, 5
Answer (C)
When a subquery uses values from outer query, the subquery is called correlated subquery. The correlated subquery is evaluated once for each row processed by the outer query.
The outer query selects 4 entries (with pids as 0, 1, 5, 3) from Reservation table. Out of these selected entries, the subquery returns Non-Null values only for 1 and 3.
18) Which of the following concurrency control protocols ensure both conflict serialzability and freedom from deadlock?
I. 2-phase locking
II. Time-stamp ordering
(A) I only
(B) II only
(C) Both I and II
(D) Neither I nor II
Answer (B)
2 Phase Locking (2PL) is a concurrency control method that guarantees serializability. The protocol utilizes locks, applied by a transaction to data, which may block (interpreted as signals to stop) other transactions from accessing the same data during the transaction’s life. 2PL may be lead to deadlocks that result from the mutual blocking of two or more transactions. See the following situation, neither T3 nor T4 can make progress.
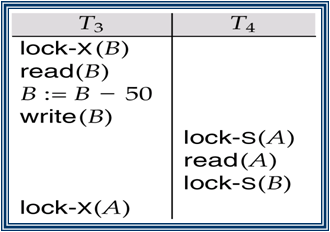
Timestamp-based concurrency control algorithm is a non-lock concurrency control method. In Timestamp based method, deadlock cannot occur as no transaction ever waits.
19) Consider the following schedule for transactions T1, T2 and T3:

Which one of the schedules below is the correct serialization of the above?
(A)T1 T3T2
T3T2
(B)T2T1T3
(C)T2T3T1
(D)T3T1T2
Answer (A)
T1 can complete before T2 and T3 as there is no conflict between Write(X) of T1 and the operations in T2 and T3 which occur before Write(X) of T1 in the above diagram.
T3 should can complete before T2 as the Read(Y) of T3 doesn’t conflict with Read(Y) of T2. Similarly, Write(X) of T3 doesn’t conflict with Read(Y) and Write(Y) operations of T2.
Another way to solve this question is to create a dependency graph and topologically sort the dependency graph. After topologically sorting, we can see the sequence T1, T3, T2.
20) The following functional dependencies hold for relations R(A, B, C) and S(B, D, E):
B A,
A C
The relation R contains 200 tuples and the rel ation S contains 100 tuples. What is the
maximum number of tuples possible in the natural join R S (R natural join S)
S (R natural join S)
(A) 100
(B) 200
(D) 300
(D) 2000
Answer (A)
From the given set of functional dependencies, it can be observed that B is a candidate key of R. So all 200 values of B must be unique in R. There is no functional dependency given for S. To get the maximum number of tuples in output, there can be two possibilities for S.
1) All 100 values of B in S are same and there is an entry in R that matches with this value. In this case, we get 100 tuples in output.
2) All 100 values of B in S are different and these values are present in R also. In this case also, we get 100 tuples.
21) Consider two transactions T1 and T2, and four schedules S1, S2, S3, S4 of T1 and T2 as given below:
T1 = R1[X] W1[X] W1[Y]
T2 = R2[X] R2[Y] W2[Y]
S1 = R1[X] R2[X] R2[Y] W1[X] W1[Y] W2[Y]
S2 = R1[X] R2[X] R2[Y] W1[X] W2[Y] W1[Y]
S3 = R1[X] W1[X] R2[X] W1[Y] R2[Y] W2[Y]
S1 = R1[X] R2[Y]R2[X]W1[X] W1[Y] W2[Y]
Which of the above schedules are conflict-serializable?
(A) S1 and S2
(B) S2 and S3
(C) S3 only
(D) S4 only
Answer (B)
There can be two possible serial schedules T1 T2 and T2 T1. The serial schedule T1 T2 has the following sequence of operations
R1[X] W1[X] W1[Y] R2[X] R2[Y] W2[Y]
And the schedule T2 T1 has the following sequence of operations.
R2[X] R2[Y] W2[Y] R1[X] W1[X] W1[Y]
The Schedule S2 is conflict-equivalent to T2 T1 and S3 is conflict-equivalent to T1 T2.
22) Let R and S be relational schemes such that R={a,b,c} and S={c}. Now consider
the following queries on the database:

(A) I and II
(B) I and III
(C) II and IV
(D) III and IV
Answer (A)
I and II describe the division operator in Relational Algebra and Tuple Relational Calculus respectively. See Page 3 of this and slide numbers 9,10 of this for more details.
23) Consider the following relational schema:
(A) Find the names of all suppliers who have supplied a non-blue part.
(B) Find the names of all suppliers who have not supplied a non-blue part.
(C) Find the names of all suppliers who have supplied only blue parts.
(D) Find the names of all suppliers who have not supplied only blue parts.
Answer (B)
The subquery “SELECT P.pid FROM Parts P WHERE P.color<> ‘blue’” gives pids of parts which are not blue. The bigger subquery “SELECT C.sid FROM Catalog C WHERE C.pid NOT IN (SELECT P.pid FROM Parts P WHERE P.color<> ‘blue’)” gives sids of all those suppliers who have supplied blue parts. The complete query gives the names of all suppliers who have not supplied a non-blue part
24) Assume that, in the suppliers relation above, each supplier and each street within a city has a unique name, and (sname, city) forms a candidate key. No other functional dependencies are implied other than those implied by primary and candidate keys. Which one of the following is TRUE about the above schema?
(A) The schema is in BCNF
(B) The schema is in 3NF but not in BCNF
(C) The schema is in 2NF but not in 3NF
(D) The schema is not in 2NF
Answer (A)
The schema is in BCNF as all attributes depend only on a superkey (Note that primary and candidate keys are also superkeys).
25) Let R and S be two relations with the following schema
R (P,Q,R1,R2,R3)
S (P,Q,S1,S2)
Where {P, Q} is the key for both schemas. Which of the following queries are equivalent?

(A) Only I and II
(B) Only I and III
(C) Only I, II and III
(D) Only I, III and IV
Answer (D)
In I, Ps from natural join of R and S are selected.
In III, all Ps from intersection of (P, Q) pairs present in R and S.
IV is also equivalent to III because (R – (R – S)) = R S.
II is not equivalent as it may also include Ps where Qs are not same in R and S.
26) Consider the following ER diagram.

The minimum number of tables needed to represent M, N, P, R1, R2 is
(A) 2
(B) 3
(C) 4
(D) 5
Answer (A)
Many-to-one and one-to-many relationship sets that are total on the many-side can be represented by adding an extra attribute to the “many” side, containing the primary key of the “one” side. Since R1 is many to one and participation of M is total, M and R1 can be combined to form the table {M1, M2, M3, P1}. N is a week entity set, so it can be combined with P.
27) Which of the following is a correct attribute set for one of the tables for the correct answer to the above question?
(A) {M1, M2, M3, P1}
(B) {M1, P1, N1, N2}
(C) {M1, P1, N1}
(D) {M1, P1}
Answer (A)
28) Consider the following relational schemes for a library database:
Book (Title, Author, Catalog_no, Publisher, Year, Price)
Collection (Title, Author, Catalog_no)
with in the following functional dependencies:
(A) Both Book and Collection are in BCNF
(B) Both Book and Collection are in 3NF only
(C) Book is in 2NF and Collection is in 3NF
(D) Both Book and Collection are in 2NF only
Answer (C)
Table Collection is in BCNF as there is only one functional dependency “Title Author –> Catalog_no” and {Author, Title} is key for collection. Book is not in BCNF because Catalog_no is not a key and there is a functional dependency “Catalog_no –> Title Author Publisher Year”. Book is not in 3NF because non-prime attributes (Publisher Year) are transitively dependent on key [Title, Author]. Book is in 2NF because every non-prime attribute of the table is either dependent on the key [Title, Author], or on another non prime attribute.
29) Which one of the following statements about normal forms is FALSE?
(a) BCNF is stricter than 3NF
(b) Lossless, dependency-preserving decomposition into 3NF is always possible
(c) Lossless, dependency-preserving decomposition into BCNF is always possible
(d) Any relation with two attributes is in BCNF
Answer (c)
It is not always possible to decompose a table in BCNF and preserve dependencies. For example, a set of functional dependencies {AB –> C, C –> B} cannot be decomposed in BCNF. See this for more details.
30) The following table has two attributes A and C where A is the primary key and C is the foreign key referencing A with on-delete cascade.
(a) (3,4) and (6,4)
(b) (5,2) and (7,2)
(c) (5,2), (7,2) and (9,5)
(d) (3,4), (4,3) and (6,4)
Answer (C)
When (2,4) is deleted. Since C is a foreign key referring A with delete on cascade, all entries with value 2 in C must be deleted. So (5, 2) and (7, 2) are deleted. As a result of this 5 and 7 are deleted from A which causes (9, 5) to be deleted.
31) The relation book (title, price) contains the titles and prices of different books. Assuming that no two books have the same price, what does the following SQL query list?
(b) Title of the fifth most inexpensive book
(c) Title of the fifth most expensive book
(d) Titles of the five most expensive books
Answer (d)
When a subquery uses values from outer query, the subquery is called correlated subquery. The correlated subquery is evaluated once for each row processed by the outer query.
The outer query selects all titles from book table. For every selected book, the subquery returns count of those books which are more expensive than the selected book. The where clause of outer query will be true for 5 most expensive book. For example count (*) will be 0 for the most expensive book and count(*) will be 1 for second most expensive book.
32) Consider the following log sequence of two transactions on a bank account, with initial balance 12000, that transfer 2000 to a mortgage payment and then apply a 5% interest.
(A) We must redo log record 6 to set B to 10500
(B) We must undo log record 6 to set B to 10000 and then redo log records 2 and 3
(C) We need not redo log records 2 and 3 because transaction T1 has committed
(D) We can apply redo and undo operations in arbitrary order because they are idempotent.
Answer (C)
Once a transaction is committed, no need to redo or undo operations.
33) Consider the relation enrolled (student, course) in which (student, course) is the primary key, and the relation paid (student, amount) where student is the primary key. Assume no null values and no foreign keys or integrity constraints. Given the following four queries:
(A) All queries return identical row sets for any database
(B) Query2 and Query4 return identical row sets for all databases but there exist databases for which Query1 and Query2 return different row sets.
(C) There exist databases for which Query3 returns strictly fewer rows than Query2.
(D) There exist databases for which Query4 will encounter an integrity violation at runtime.
Answer (A)
The output of Query2, Query3 and Query4 will be identical. Query1 may produce duplicate rows. But rowset produced by all of them will be same.
34) Consider the relation enrolled(student, course) in which (student, course) is the primary key, and the relation paid(student, amount), where student is the primary key. Assume no null values and no foreign keys or integrity constraints. Assume that amounts 6000, 7000, 8000, 9000 and 10000 were each paid by 20% of the students. Consider these query plans (Plan 1 on left, Plan 2 on right) to “list all courses taken by students who have paid more than x”.

A disk seek takes 4ms, disk data transfer bandwidth is 300 MB/s and checking a tuple to see if amount is greater than x takes 10 micro-seconds. Which of the following statements is correct?
(A) Plan 1 and Plan 2 will not output identical row sets for all databases.
(B) A course may be listed more than once in the output of Plan 1 for some databases
(C) For x = 5000, Plan 1 executes faster than Plan 2 for all databases.
(D) For x = 9000, Plan I executes slower than Plan 2 for all databases.
Answer (C)
Assuming that large enough memory is available for all data needed. Both plans need to load both tables courses and enrolled. So disk access time is same for both plans.
Plan 2 does lesser number of comparisons compared to plan 1.
1) Join operation will require more comparisons as the second table will have more rows in plan 2 compared to plan 1.
2) The joined table of two tables will will have more rows, so more comparisons are needed to find amounts greater than x.
35) The following functional dependencies are given:
(A)CF+ = {ACDEFG}
(B)BG+ = {ABCDG}
(C)AF+ = {ACDEFG}
(D)AB+ = {ABCDFG}
Answer (C)
Closure of AF or AF+ = {ADEF}, closure of AF doesn’t contain C and G.
Option (D) also looks correct. AB+ = {ABCDG}, closure of AB doesn’t contain F.
employee (name, salary, deptno) and
department (deptno, deptname, address)
Which of the following queries cannot be expressed using the basic relational algebra
operations (U, -, x,
, p)? (GATE CS 2000)(a) Department address of every employee
(b) Employees whose name is the same as their department name
(c) The sum of all employees’ salaries
(d) All employees of a given department
Answer: (c)
Explanation:
The six basic operators of relational algebra are the selection(
), the projection(),
the Cartesian product (x) (also called the cross product or cross
join), the set union (U), the set difference (-), and the rename (p).
These six operators are fundamental in the sense that none of them can
be omitted without losing expressive power. Many other operators have
been defined in terms of these six. Among the most important are set
intersection, division, and the natural join, but aggregation is not
possible with these basic relational algebra operations. So, we cannot
run sum of all employees’ salaries with the six operations.References:
http://en.wikipedia.org/wiki/Relational_algebra
http://faculty.ksu.edu.sa/zitouni/203%20Haseb%20%20Lecture%20Notes/Relional%20Algebra.pdf
2. Given the following relation instance.
x y z 1 4 2 1 5 3 1 6 3 3 2 2Which of the following functional dependencies are satisfied by the instance? (GATE CS 2000)
(a) XY -> Z and Z -> Y
(b) YZ -> X and Y -> Z
(c) YZ -> X and X -> Z
(d) XZ -> Y and Y -> X
Answer: (b)
Explanation:
A functional dependency (FD) is a constraint between two sets of attributes in a relation from a database. A FD X->Y require that the value of X uniquely determines the value of Y where X and Y are set of attributes. FD is a generalization of the notion of a key.
Given that X, Y, and Z are sets of attributes in a relation R, one can derive several properties of functional dependencies. Among the most important are Armstrong’s axioms, which are used in database normalization:
* Subset Property (Axiom of Reflexivity): If Y is a subset of X, then X ? Y * Augmentation (Axiom of Augmentation): If X -> Y, then XZ -> YZ * Transitivity (Axiom of Transitivity): If X -> Y and Y -> Z, then X -> ZFrom these rules, we can derive these secondary rules:
* Union: If X -> Y and X -> Z, then X -> YZ * Decomposition: If X -> YZ, then X -> Y and X -> Z * Pseudotransitivity: If X -> Y and YZ -> W, then XZ -> WIn the above question, Y uniquely determines X and Z, for a given value of Y you can easily find out values of X and Z.
So, Y -> X and Y -> Z hold for above schema.
From rule of augmentation we can say YZ->X. If we understand the notion of FD, we don’t need to apply axioms to find out which option is true, just by looking at the schema and options we can say that (b) is true.
References:
http://www.cse.iitb.ac.in/~sudarsha/db-book/slide-dir/ch7.pdf
http://en.wikipedia.org/wiki/Functional_dependency
3. Given relations r(w, x) and s(y, z), the result of
select distinct w, x
from r, s
is guaranteed to be same as r, provided (GATE CS 2000)
(a) r has no duplicates and s is non-empty
(b) r and s have no duplicates
(c) s has no duplicates and r is non-empty
(d) r and s have the same number of tuples
Answer: (a)
Explanation:
The query selects all attributes of r. Since we have distinct in query, result can be equal to r only if r doesn’t have duplicates.
If we do not give any attribute on which we want to join two tables, then the queries like above become equivalent to Cartesian product. Cartisian product of two sets will be empty if any of the two sets is empty. So, s should have atleast one record to get all rows of r.
4. In SQL, relations can contain null values, and comparisons with null values are treated as unknown. Suppose all comparisons with a null value are treated as false. Which of the
following pairs is not equivalent? (GATE CS 2000)
(a) x = 5, not (not (x = 5)
(b) x = 5, x > 4 and x < 6, where x is an integer
(c) x < 5, not(x = 5)
(d) None of the above
Answer (c)
Explanation:
It doesn’t need much explanation. For all values smaller than 5, x < 5 will always be true but x = 5 will be false.
5. Consider a schema R(A, B, C, D) and functional dependencies A -> B and C -> D. Then the decomposition of R into R1 (A, B) and R2(C, D) is (GATE CS 2001)
a) dependency preserving and loss less join
b) loss less join but not dependency preserving
c) dependency preserving but not loss less join
d) not dependency preserving and not loss less join
Answer: (c)
Explanation:
Dependency Preserving Decomposition:
Decomposition of R into R1 and R2 is a dependency preserving decomposition if closure of functional dependencies after decomposition is same as closure of of FDs before decomposition.
A simple way is to just check whether we can derive all the original FDs from the FDs present after decomposition.
In the above question R(A, B, C, D) is decomposed into R1 (A, B) and R2(C, D) and there are only two FDs A -> B and C -> D. So, the decomposition is dependency preserving
Lossless-Join Decomposition:
Decomposition of R into R1 and R2 is a lossless-join decomposition if at least one of the following functional dependencies are in F+ (Closure of functional dependencies)
R1In the above question R(A, B, C, D) is decomposed into R1 (A, B) and R2(C, D), and R1R1 OR R1
R2 is empty. So, the decomposition is not lossless. References:
http://www.cs.sfu.ca/CC/354/han/materia/notes/354notes-chapter6/node1.html
6) Which of the following statements are TRUE about an SQL query?
P: An SQL query can contain a HAVING clause even if it does not a GROUP BY clause
Q: An SQL query can contain a HAVING clause only if it has a GROUP BY clause
R: All attributes used in the GROUP BY clause must appear in the SELECT clause
S: Not all attributes used in the GROUP BY clause need to apper in the SELECT clause
(A) P and R
(B) P and S
(C) Q and R
(D) Q and S
Answer (B)
P is correct. HAVING clause can also be used with aggregate function. If we use a HAVING clause without a GROUP BY clause, the HAVING condition applies to all rows that satisfy the search condition. In other words, all rows that satisfy the search condition make up a single group. See this for more details.
S is correct. To verify S, try following queries in SQL.
CREATE TABLE temp
(
id INT,
name VARCHAR(100)
);
INSERT INTO temp VALUES (1, "abc");
INSERT INTO temp VALUES (2, "abc");
INSERT INTO temp VALUES (3, "bcd");
INSERT INTO temp VALUES (4, "cde");
SELECT Count(*)
FROM temp
GROUP BY name;
Output:
count(*) -------- 2 1 1
7) Given the basic ER and relational models, which of the following is INCORRECT?
(A) An attributes of an entity can have more that one value
(B) An attribute of an entity can be composite
(C) In a row of a relational table, an attribute can have more than one value
(D) In a row of a relational table, an attribute can have exactly one value or a NULL value
Answer (C)
The term ‘entity’ belongs to ER model and the term ‘relational table’ belongs to relational model.
A and B both are true. ER model supports both multivalued and composite attributes See this for more details.
(C) is false and (D) is true. In Relation model, an entry in relational table can can have exactly one value or a NULL.
8) Suppose (A, B) and (C,D) are two relation schemas. Let r1 and r2 be the corresponding relation instances. B is a foreign key that refers to C in r2. If data in r1 and r2 satisfy referential integrity constraints, which of the following is ALWAYS TRUE?
Answer (A)
B is a foreign key in r1 that refers to C in r2. r1 and r2 satisfy referential integrity constraints. So every value that exists in column B of r1 must also exist in column C of r2.
9) Which of the following is TRUE?
(A) Every relation in 2NF is also in BCNF
(B) A relation R is in 3NF if every non-prime attribute of R is fully functionally dependent on every key of R
(C) Every relation in BCNF is also in 3NF
(D) No relation can be in both BCNF and 3NF
Answer (C)
BCNF is a stronger version 3NF. So every relation in BCNF will also be in 3NF.
10) Consider the following transactions with data items P and Q initialized to zero:
T1: read (P) ;
read (Q) ;
if P = 0 then Q : = Q + 1 ;
write (Q) ;
T2: read (Q) ;
read (P) ;
if Q = 0 then P : = P + 1 ;
write (P) ;
Any non-serial interleaving of T1 and T2 for concurrent execution leads to(A) A serializable schedule
(B) A schedule that is not conflict serializable
(C) A conflict serializable schedule
(D) A schedule for which a precedence graph cannot be drawn
Answer (B)
Two or more actions are said to be in conflict if:
1) The actions belong to different transactions.
2) At least one of the actions is a write operation.
3) The actions access the same object (read or write).
The schedules S1 and S2 are said to be conflict-equivalent if the following conditions are satisfied:
1) Both schedules S1 and S2 involve the same set of transactions (including ordering of actions within each transaction).
2) The order of each pair of conflicting actions in S1 and S2 are the same.
A schedule is said to be conflict-serializable when the schedule is conflict-equivalent to one or more serial schedules.
Source: Wiki Page for Schedule
In the given scenario, there are two possible serial schedules:
1) T1 followed by T2
2) T2 followed by T1.
In both of the serial schedules, one of the transactions reads the value written by other transaction as a first step. Therefore, any non-serial interleaving of T1 and T2 will not be conflict serializable.
11) Consider the following relations A, B, C. How many tuples does the result of the following relational algebra expression contain? Assume that the schema of A U B is the same as that of A.
Table A Id Name Age ---------------- 12 Arun 60 15 Shreya 24 99 Rohit 11 Table B Id Name Age ---------------- 15 Shreya 24 25 Hari 40 98 Rohit 20 99 Rohit 11 Table C Id Phone Area ----------------- 10 2200 02 99 2100 01(A) 7
(B) 4
(C) 5
(D) 9
Answer (A)
Result of AUB will be following table Id Name Age ---------------- 12 Arun 60 15 Shreya 24 99 Rohit 11 25 Hari 40 98 Rohit 20 The result of given relational algebra expression will be Id Name Age Id Phone Area --------------------------------- 12 Arun 60 10 2200 02 15 Shreya 24 10 2200 02 99 Rohit 11 10 2200 02 25 Hari 40 10 2200 02 98 Rohit 20 10 2200 02 99 Rohit 11 99 2100 01 98 Rohit 20 99 2100 01
12) Consider the above tables A, B and C. How many tuples does the result of the following SQL query contains?
SELECT A.id
FROM A
WHERE A.age > ALL (SELECT B.age
FROM B
WHERE B. name = "arun")
(A) 4(B) 3
(C) 0
(D) 1
Answer (B)
The meaning of “ALL” is the A.Age should be greater than all the values returned by the subquery. There is no entry with name “arun” in table B. So the subquery will return NULL. If a subquery returns NULL, then the condition becomes true for all rows of A (See this for details). So all rows of table A are selected.
13. Consider a relational table with a single record for each registered student with the following attributes.
1. Registration_Number:< Unique registration number for each registered student
2. UID: Unique Identity number, unique at the national level for each citizen
3. BankAccount_Number: Unique account number at the bank. A student can have multiple accounts or joint accounts. This attributes stores the primary account number
4. Name: Name of the Student
5. Hostel_Room: Room number of the hostel
Which of the following options is INCORRECT?
(A) BankAccount_Number is a candidate key
(B) Registration_Number can be a primary key
(C) UID is a candidate key if all students are from the same country
(D) If S is a superkey such that S
UID is NULL then S UID is also a superkey Answer (A)
A Candidate Key value must uniquely identify the corresponding row in table. BankAccount_Number is not a candidate key. As per the question “A student can have multiple accounts or joint accounts. This attributes stores the primary account number”. If two students have a joint account and if the joint account is their primary account, then BankAccount_Number value cannot uniquely identify a row.
14) Consider a relational table r with sufficient number of records, having attributes A1, A2,…, An and let 1 <= p <= n. Two queries Q1 and Q2 are given below.
The database can be configured to do ordered indexing on Ap or hashing on Ap. Which of the following statements is TRUE?
(A) Ordered indexing will always outperform hashing for both queries
(B) Hashing will always outperform ordered indexing for both queries
(C) Hashing will outperform ordered indexing on Q1, but not on Q2
(D) Hashing will outperform ordered indexing on Q2, but not on Q1.
Answer (C)
If record are accessed for a particular value from table, hashing will do better. If records are accessed in a range of values, ordered indexing will perform better. See this for more details.
15) Database table by name Loan_Records is given below.
Borrower Bank_Manager Loan_Amount Ramesh Sunderajan 10000.00 Suresh Ramgopal 5000.00 Mahesh Sunderajan 7000.00What is the output of the following SQL query?
SELECT Count(*)
FROM ( (SELECT Borrower, Bank_Manager
FROM Loan_Records) AS S
NATURAL JOIN (SELECT Bank_Manager,
Loan_Amount
FROM Loan_Records) AS T );
(A) 3(B) 9
(C) 5
(D) 6
Answer (C)
Following will be contents of temporary table S
Borrower Bank_Manager -------------------------- Ramesh Sunderajan Suresh Ramgqpal Mahesh SunderjanFollowing will be contents of temporary table T
Bank_Manager Loan_Amount --------------------------- Sunderajan 10000.00 Ramgopal 5000.00 Sunderjan 7000.00Following will be the result of natural join of above two tables. The key thing to note is that the natural join happens on column name with same name which is Bank_Manager in the above example. “Sunderjan” appears two times in Bank_Manager column, so their will be four entries with Bank_Manager as “Sunderjan”.
Borrower Bank_Manager Load_Amount ------------------------------------ Ramesh Sunderajan 10000.00 Ramesh Sunderajan 7000.00 Suresh Ramgopal 5000.00 Mahesh Sunderajan 10000.00 Mahesh Sunderajan 7000.00
16) the table at any point in time. Using MX and MY, new records are inserted in the table 128 times with X and Y values being MX+1, 2*MY+1 respectively. It may be noted that each time after the insertion, values of MX and MY change. What will be the output of the following SQL query after the steps mentioned above are carried out?
SELECT Y FROM T WHERE X=7;(A) 127
(B) 255
(C) 129
(D) 257
Answer (A)
X Y ------- 1 1 2 3 3 7 4 15 5 31 6 63 7 127 ...... ......
17) A relational schema for a train reservation database is given below.
Passenger (pid, pname, age)
Reservation (pid, class, tid)
Table: Passenger pid pname age ----------------- 0 Sachin 65 1 Rahul 66 2 Sourav 67 3 Anil 69 Table : Reservation pid class tid --------------- 0 AC 8200 1 AC 8201 2 SC 8201 5 AC 8203 1 SC 8204 3 AC 8202 What pids are returned by the following SQL query for the above instance of the tables?
SLECT pid FROM Reservation , WHERE class ‘AC’ AND EXISTS (SELECT * FROM Passenger WHERE age > 65 AND Passenger. pid = Reservation.pid) (A) 1, 0
(B) 1, 2
(C) 1, 3
(S) 1, 5
Answer (C)
When a subquery uses values from outer query, the subquery is called correlated subquery. The correlated subquery is evaluated once for each row processed by the outer query.
The outer query selects 4 entries (with pids as 0, 1, 5, 3) from Reservation table. Out of these selected entries, the subquery returns Non-Null values only for 1 and 3.
18) Which of the following concurrency control protocols ensure both conflict serialzability and freedom from deadlock?
I. 2-phase locking
II. Time-stamp ordering
(A) I only
(B) II only
(C) Both I and II
(D) Neither I nor II
Answer (B)
2 Phase Locking (2PL) is a concurrency control method that guarantees serializability. The protocol utilizes locks, applied by a transaction to data, which may block (interpreted as signals to stop) other transactions from accessing the same data during the transaction’s life. 2PL may be lead to deadlocks that result from the mutual blocking of two or more transactions. See the following situation, neither T3 nor T4 can make progress.
Timestamp-based concurrency control algorithm is a non-lock concurrency control method. In Timestamp based method, deadlock cannot occur as no transaction ever waits.
19) Consider the following schedule for transactions T1, T2 and T3:
Which one of the schedules below is the correct serialization of the above?
(A)T1
T3T2(B)T2
T1T3(C)T2
T3T1(D)T3
T1T2Answer (A)
T1 can complete before T2 and T3 as there is no conflict between Write(X) of T1 and the operations in T2 and T3 which occur before Write(X) of T1 in the above diagram.
T3 should can complete before T2 as the Read(Y) of T3 doesn’t conflict with Read(Y) of T2. Similarly, Write(X) of T3 doesn’t conflict with Read(Y) and Write(Y) operations of T2.
Another way to solve this question is to create a dependency graph and topologically sort the dependency graph. After topologically sorting, we can see the sequence T1, T3, T2.
20) The following functional dependencies hold for relations R(A, B, C) and S(B, D, E):
B
A,A
CThe relation R contains 200 tuples and the rel ation S contains 100 tuples. What is the
maximum number of tuples possible in the natural join R
S (R natural join S)(A) 100
(B) 200
(D) 300
(D) 2000
Answer (A)
From the given set of functional dependencies, it can be observed that B is a candidate key of R. So all 200 values of B must be unique in R. There is no functional dependency given for S. To get the maximum number of tuples in output, there can be two possibilities for S.
1) All 100 values of B in S are same and there is an entry in R that matches with this value. In this case, we get 100 tuples in output.
2) All 100 values of B in S are different and these values are present in R also. In this case also, we get 100 tuples.
21) Consider two transactions T1 and T2, and four schedules S1, S2, S3, S4 of T1 and T2 as given below:
T1 = R1[X] W1[X] W1[Y]
T2 = R2[X] R2[Y] W2[Y]
S1 = R1[X] R2[X] R2[Y] W1[X] W1[Y] W2[Y]
S2 = R1[X] R2[X] R2[Y] W1[X] W2[Y] W1[Y]
S3 = R1[X] W1[X] R2[X] W1[Y] R2[Y] W2[Y]
S1 = R1[X] R2[Y]R2[X]W1[X] W1[Y] W2[Y]
Which of the above schedules are conflict-serializable?
(A) S1 and S2
(B) S2 and S3
(C) S3 only
(D) S4 only
Answer (B)
There can be two possible serial schedules T1 T2 and T2 T1. The serial schedule T1 T2 has the following sequence of operations
R1[X] W1[X] W1[Y] R2[X] R2[Y] W2[Y]
And the schedule T2 T1 has the following sequence of operations.
R2[X] R2[Y] W2[Y] R1[X] W1[X] W1[Y]
The Schedule S2 is conflict-equivalent to T2 T1 and S3 is conflict-equivalent to T1 T2.
22) Let R and S be relational schemes such that R={a,b,c} and S={c}. Now consider
the following queries on the database:
IV) SELECT R.a, R.b
FROM R,S
WHERE R.c=S.c
Which of the above queries are equivalent?(A) I and II
(B) I and III
(C) II and IV
(D) III and IV
Answer (A)
I and II describe the division operator in Relational Algebra and Tuple Relational Calculus respectively. See Page 3 of this and slide numbers 9,10 of this for more details.
23) Consider the following relational schema:
Suppliers(sid:integer, sname:string, city:string, street:string) Parts(pid:integer, pname:string, color:string) Catalog(sid:integer, pid:integer, cost:real)Consider the following relational query on the above database:
SELECT S.sname
FROM Suppliers S
WHERE S.sid NOT IN (SELECT C.sid
FROM Catalog C
WHERE C.pid NOT IN (SELECT P.pid
FROM Parts P
WHERE P.color<> 'blue'))
Assume that relations corresponding to the above schema are
not empty. Which one of the following is the correct interpretation of
the above query?(A) Find the names of all suppliers who have supplied a non-blue part.
(B) Find the names of all suppliers who have not supplied a non-blue part.
(C) Find the names of all suppliers who have supplied only blue parts.
(D) Find the names of all suppliers who have not supplied only blue parts.
Answer (B)
The subquery “SELECT P.pid FROM Parts P WHERE P.color<> ‘blue’” gives pids of parts which are not blue. The bigger subquery “SELECT C.sid FROM Catalog C WHERE C.pid NOT IN (SELECT P.pid FROM Parts P WHERE P.color<> ‘blue’)” gives sids of all those suppliers who have supplied blue parts. The complete query gives the names of all suppliers who have not supplied a non-blue part
24) Assume that, in the suppliers relation above, each supplier and each street within a city has a unique name, and (sname, city) forms a candidate key. No other functional dependencies are implied other than those implied by primary and candidate keys. Which one of the following is TRUE about the above schema?
(A) The schema is in BCNF
(B) The schema is in 3NF but not in BCNF
(C) The schema is in 2NF but not in 3NF
(D) The schema is not in 2NF
Answer (A)
The schema is in BCNF as all attributes depend only on a superkey (Note that primary and candidate keys are also superkeys).
25) Let R and S be two relations with the following schema
R (P,Q,R1,R2,R3)
S (P,Q,S1,S2)
Where {P, Q} is the key for both schemas. Which of the following queries are equivalent?
(A) Only I and II
(B) Only I and III
(C) Only I, II and III
(D) Only I, III and IV
Answer (D)
In I, Ps from natural join of R and S are selected.
In III, all Ps from intersection of (P, Q) pairs present in R and S.
IV is also equivalent to III because (R – (R – S)) = R
S.II is not equivalent as it may also include Ps where Qs are not same in R and S.
26) Consider the following ER diagram.
The minimum number of tables needed to represent M, N, P, R1, R2 is
(A) 2
(B) 3
(C) 4
(D) 5
Answer (A)
Many-to-one and one-to-many relationship sets that are total on the many-side can be represented by adding an extra attribute to the “many” side, containing the primary key of the “one” side. Since R1 is many to one and participation of M is total, M and R1 can be combined to form the table {M1, M2, M3, P1}. N is a week entity set, so it can be combined with P.
27) Which of the following is a correct attribute set for one of the tables for the correct answer to the above question?
(A) {M1, M2, M3, P1}
(B) {M1, P1, N1, N2}
(C) {M1, P1, N1}
(D) {M1, P1}
Answer (A)
28) Consider the following relational schemes for a library database:
Book (Title, Author, Catalog_no, Publisher, Year, Price)
Collection (Title, Author, Catalog_no)
with in the following functional dependencies:
I. Title Author --> Catalog_no II. Catalog_no --> Title Author Publisher Year III. Publisher Title Year --> PriceAssume {Author, Title} is the key for both schemes. Which of the following statements is true?
(A) Both Book and Collection are in BCNF
(B) Both Book and Collection are in 3NF only
(C) Book is in 2NF and Collection is in 3NF
(D) Both Book and Collection are in 2NF only
Answer (C)
Table Collection is in BCNF as there is only one functional dependency “Title Author –> Catalog_no” and {Author, Title} is key for collection. Book is not in BCNF because Catalog_no is not a key and there is a functional dependency “Catalog_no –> Title Author Publisher Year”. Book is not in 3NF because non-prime attributes (Publisher Year) are transitively dependent on key [Title, Author]. Book is in 2NF because every non-prime attribute of the table is either dependent on the key [Title, Author], or on another non prime attribute.
29) Which one of the following statements about normal forms is FALSE?
(a) BCNF is stricter than 3NF
(b) Lossless, dependency-preserving decomposition into 3NF is always possible
(c) Lossless, dependency-preserving decomposition into BCNF is always possible
(d) Any relation with two attributes is in BCNF
Answer (c)
It is not always possible to decompose a table in BCNF and preserve dependencies. For example, a set of functional dependencies {AB –> C, C –> B} cannot be decomposed in BCNF. See this for more details.
30) The following table has two attributes A and C where A is the primary key and C is the foreign key referencing A with on-delete cascade.
A C ----- 2 4 3 4 4 3 5 2 7 2 9 5 6 4The set of all tuples that must be additionally deleted to preserve referential integrity when the tuple (2,4) is deleted is:
(a) (3,4) and (6,4)
(b) (5,2) and (7,2)
(c) (5,2), (7,2) and (9,5)
(d) (3,4), (4,3) and (6,4)
Answer (C)
When (2,4) is deleted. Since C is a foreign key referring A with delete on cascade, all entries with value 2 in C must be deleted. So (5, 2) and (7, 2) are deleted. As a result of this 5 and 7 are deleted from A which causes (9, 5) to be deleted.
31) The relation book (title, price) contains the titles and prices of different books. Assuming that no two books have the same price, what does the following SQL query list?
select title
from book as B
where (select count(*)
from book as T
where T.price > B.price) < 5
(a) Titles of the four most expensive books(b) Title of the fifth most inexpensive book
(c) Title of the fifth most expensive book
(d) Titles of the five most expensive books
Answer (d)
When a subquery uses values from outer query, the subquery is called correlated subquery. The correlated subquery is evaluated once for each row processed by the outer query.
The outer query selects all titles from book table. For every selected book, the subquery returns count of those books which are more expensive than the selected book. The where clause of outer query will be true for 5 most expensive book. For example count (*) will be 0 for the most expensive book and count(*) will be 1 for second most expensive book.
32) Consider the following log sequence of two transactions on a bank account, with initial balance 12000, that transfer 2000 to a mortgage payment and then apply a 5% interest.
1. T1 start 2. T1 B old=12000 new=10000 3. T1 M old=0 new=2000 4. T1 commit 5. T2 start 6. T2 B old=10000 new=10500 7. T2 commitSuppose the database system crashes just before log record 7 is written. When the system is restarted, which one statement is true of the recovery procedure?
(A) We must redo log record 6 to set B to 10500
(B) We must undo log record 6 to set B to 10000 and then redo log records 2 and 3
(C) We need not redo log records 2 and 3 because transaction T1 has committed
(D) We can apply redo and undo operations in arbitrary order because they are idempotent.
Answer (C)
Once a transaction is committed, no need to redo or undo operations.
33) Consider the relation enrolled (student, course) in which (student, course) is the primary key, and the relation paid (student, amount) where student is the primary key. Assume no null values and no foreign keys or integrity constraints. Given the following four queries:
Query1: select student from enrolled where student in (select student from paid)
Query2: select student from paid where student in (select student from enrolled)
Query3: select E.student from enrolled E, paid P where E.student = P.student
Query4: select student from paid where exists
(select * from enrolled where enrolled.student = paid.student)
Which one of the following statements is correct?(A) All queries return identical row sets for any database
(B) Query2 and Query4 return identical row sets for all databases but there exist databases for which Query1 and Query2 return different row sets.
(C) There exist databases for which Query3 returns strictly fewer rows than Query2.
(D) There exist databases for which Query4 will encounter an integrity violation at runtime.
Answer (A)
The output of Query2, Query3 and Query4 will be identical. Query1 may produce duplicate rows. But rowset produced by all of them will be same.
Table enrolled student course ---------------- abc c1 xyz c1 abc c2 pqr c1 Table paid student amount ----------------- abc 20000 xyz 10000 rst 10000 Output of Query 1 abc abc xyz Output of Query 2 abc xyz Output of Query 3 abc xyz Output of Query 4 abc xyz
34) Consider the relation enrolled(student, course) in which (student, course) is the primary key, and the relation paid(student, amount), where student is the primary key. Assume no null values and no foreign keys or integrity constraints. Assume that amounts 6000, 7000, 8000, 9000 and 10000 were each paid by 20% of the students. Consider these query plans (Plan 1 on left, Plan 2 on right) to “list all courses taken by students who have paid more than x”.
A disk seek takes 4ms, disk data transfer bandwidth is 300 MB/s and checking a tuple to see if amount is greater than x takes 10 micro-seconds. Which of the following statements is correct?
(A) Plan 1 and Plan 2 will not output identical row sets for all databases.
(B) A course may be listed more than once in the output of Plan 1 for some databases
(C) For x = 5000, Plan 1 executes faster than Plan 2 for all databases.
(D) For x = 9000, Plan I executes slower than Plan 2 for all databases.
Answer (C)
Assuming that large enough memory is available for all data needed. Both plans need to load both tables courses and enrolled. So disk access time is same for both plans.
Plan 2 does lesser number of comparisons compared to plan 1.
1) Join operation will require more comparisons as the second table will have more rows in plan 2 compared to plan 1.
2) The joined table of two tables will will have more rows, so more comparisons are needed to find amounts greater than x.
35) The following functional dependencies are given:
ABWhich one of the following options is false?
(A)CF+ = {ACDEFG}
(B)BG+ = {ABCDG}
(C)AF+ = {ACDEFG}
(D)AB+ = {ABCDFG}
Answer (C)
Closure of AF or AF+ = {ADEF}, closure of AF doesn’t contain C and G.
Option (D) also looks correct. AB+ = {ABCDG}, closure of AB doesn’t contain F.
No comments:
Post a Comment