Cache "miss rate" is used as a measure of cache performance.
Given 10 accesses to a cache, 9 hits and 1 miss,
the miss rate = 1/10 = 10%
Because there must always be compulsory misses, the miss rate
can never be zero. On some plots below, the miss rate is 1%
meaning a 99% hit rate.
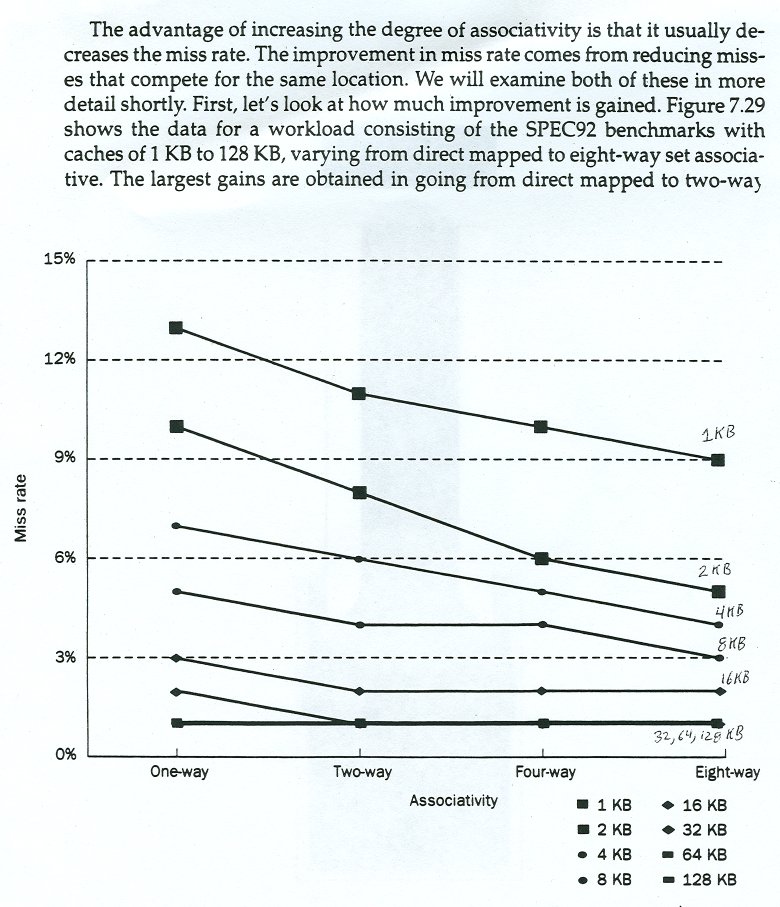
The importance of the plots is not the numbers, rather the trends.
Note that this was based on SPEC92, over 20 years ago. Programs
were much smaller back then, yet the trend for performance is the
same today. Caches are scaled up today, 1MB and 2MB caches are
common and 8MB caches are available.
Cache performance based on two factors:
1) Cache size (bigger is better)
2) Cache associativity (more is better)
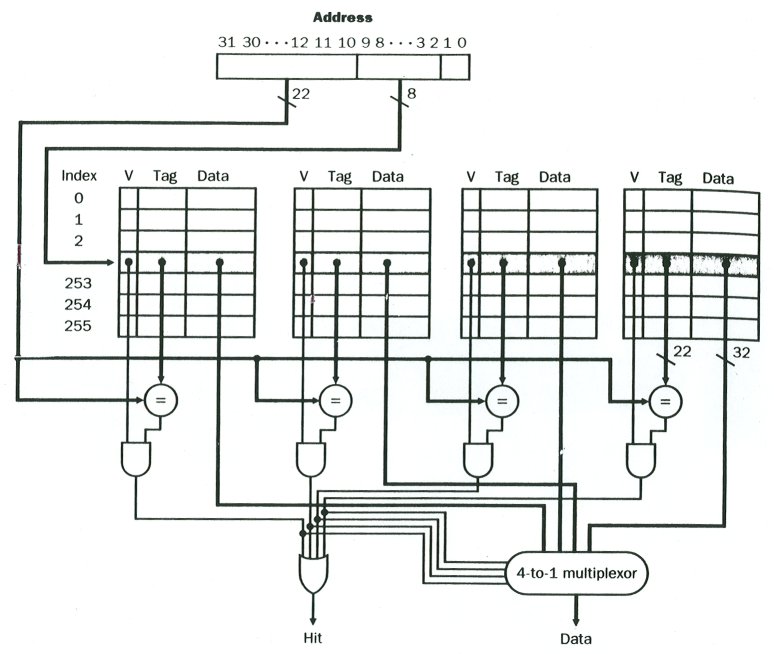
 A 4 way associative cache. Count tag equal comparators.
A 4 way associative cache. Count tag equal comparators.
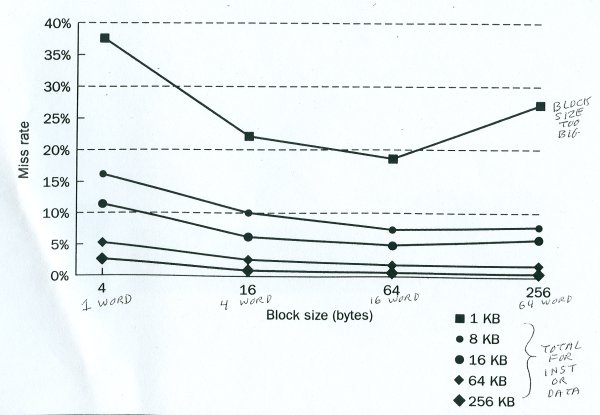
 Cache performance based on two factors:
1) cache size (bigger is better)
2) block size (more is usually better, but not for small caches!)
Cache performance based on two factors:
1) cache size (bigger is better)
2) block size (more is usually better, but not for small caches!)
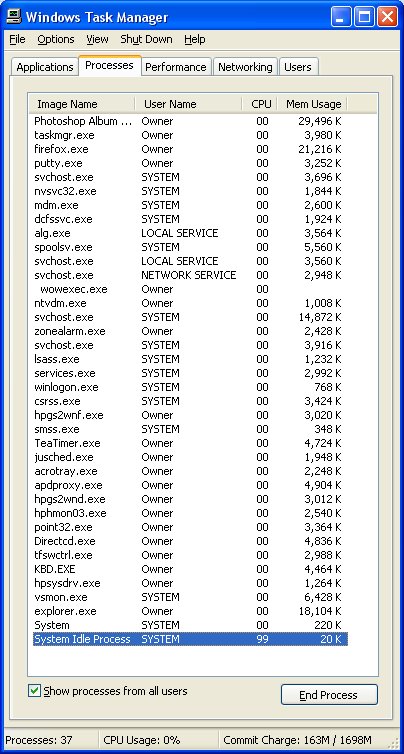
 Caches hold a small part of memory in the CPU for fast access.
The following two sets of memory usage are from my computers and
show the size of some programs on Windows and Linux.
Memory usage on Windows XP:
37 processes
Windows Explorer 18,104 KB 18 MB too big for cache
Firefox 21,216 KB
Photoshop 29,496 KB
etc.
total 163,000 KB 163MB of 512MB used.
You would want good performance by keeping most of a program
in cache. Thus, the need for caches in the megabytes.
Caches hold a small part of memory in the CPU for fast access.
The following two sets of memory usage are from my computers and
show the size of some programs on Windows and Linux.
Memory usage on Windows XP:
37 processes
Windows Explorer 18,104 KB 18 MB too big for cache
Firefox 21,216 KB
Photoshop 29,496 KB
etc.
total 163,000 KB 163MB of 512MB used.
You would want good performance by keeping most of a program
in cache. Thus, the need for caches in the megabytes.
 Memory usage on RedHat Linux:
83 processes, 3 running
X 38,119 KB way too big for cache
Firefox 20,083 KB
Gimp 5,402 KB with extras running
etc
running top reports:
306 MB memory used
195 MB memory free
14 MB memory buff
From: ps -Al ## memory size in KB
F S UID PID PPID C PRI NI ADR SZ WCHAN TTY TIME CMD
4 S 0 1 0 1 75 0 - 345 schedu ? 00:00:04 init
1 S 0 2 1 0 75 0 - 0 contex ? 00:00:00 keventd
1 S 0 3 1 0 75 0 - 0 schedu ? 00:00:00 kapmd
1 S 0 4 1 0 94 19 - 0 ksofti ? 00:00:00 ksoftirqd_C
1 S 0 9 1 0 85 0 - 0 bdflus ? 00:00:00 bdflush
1 S 0 5 1 0 75 0 - 0 schedu ? 00:00:00 kswapd
1 S 0 6 1 0 75 0 - 0 schedu ? 00:00:00 kscand/DMA
1 S 0 7 1 0 75 0 - 0 schedu ? 00:00:00 kscand/Norm
1 S 0 8 1 0 75 0 - 0 schedu ? 00:00:00 kscand/High
1 S 0 10 1 0 75 0 - 0 schedu ? 00:00:00 kupdated
1 S 0 11 1 0 85 0 - 0 md_thr ? 00:00:00 mdrecoveryd
1 S 0 15 1 0 75 0 - 0 end ? 00:00:00 kjournald
1 S 0 73 1 0 85 0 - 0 end ? 00:00:00 khubd
1 S 0 1012 1 0 75 0 - 0 end ? 00:00:00 kjournald
1 S 0 1137 1 0 85 0 - 0 end ? 00:00:00 kjournald
1 S 0 3676 1 0 84 0 - 524 schedu ? 00:00:00 dhclient
5 S 0 3727 1 0 75 0 - 369 schedu ? 00:00:00 syslogd
5 S 0 3731 1 0 75 0 - 344 do_sys ? 00:00:00 klogd
5 S 32 3749 1 0 75 0 - 388 schedu ? 00:00:00 portmap
5 S 29 3768 1 0 75 0 - 391 schedu ? 00:00:00 rpc.statd
1 S 0 3812 1 0 75 0 - 0 end ? 00:00:00 rpciod
1 S 0 3813 1 0 85 0 - 0 schedu ? 00:00:00 lockd
5 S 0 3825 1 0 84 0 - 343 schedu ? 00:00:00 apmd
5 S 0 3841 1 0 85 0 - 5014 schedu ? 00:00:00 ypbind
1 S 0 3945 1 0 75 0 - 372 pipe_w ? 00:00:00 automount
1 S 0 3947 1 0 75 0 - 372 pipe_w ? 00:00:00 automount
1 S 0 3949 1 0 75 0 - 372 pipe_w ? 00:00:00 automount
5 S 0 3968 1 0 85 0 - 879 schedu ? 00:00:00 sshd
5 S 38 3989 1 0 75 0 - 601 schedu ? 00:00:00 ntpd
1 S 0 4013 1 0 75 0 - 0 schedu ? 00:00:00 afs_rxliste
1 S 0 4015 1 0 75 0 - 0 end ? 00:00:00 afs_callbac
1 S 0 4017 1 0 75 0 - 0 schedu ? 00:00:00 afs_rxevent
1 S 0 4019 1 0 75 0 - 0 schedu ? 00:00:00 afsd
1 S 0 4021 1 0 75 0 - 0 schedu ? 00:00:00 afs_checkse
1 S 0 4023 1 0 75 0 - 0 end ? 00:00:00 afs_backgro
1 S 0 4025 1 0 75 0 - 0 end ? 00:00:00 afs_backgro
1 S 0 4027 1 0 75 0 - 0 end ? 00:00:00 afs_backgro
1 S 0 4029 1 0 75 0 - 0 end ? 00:00:00 afs_cachetr
5 S 0 4037 1 0 75 0 - 354 schedu ? 00:00:00 gpm
1 S 0 4046 1 0 75 0 - 358 schedu ? 00:00:00 crond
5 S 43 4078 1 0 76 0 - 1226 schedu ? 00:00:00 xfs
1 S 2 4087 1 0 85 0 - 355 schedu ? 00:00:00 atd
4 S 0 4306 1 0 82 0 - 340 schedu tty1 00:00:00 mingetty
4 S 0 4307 1 0 82 0 - 340 schedu tty2 00:00:00 mingetty
4 S 0 4308 1 0 82 0 - 340 schedu tty3 00:00:00 mingetty
4 S 0 4309 1 0 82 0 - 340 schedu tty4 00:00:00 mingetty
4 S 0 4310 1 0 82 0 - 340 schedu tty5 00:00:00 mingetty
4 S 0 4311 1 0 82 0 - 340 schedu tty6 00:00:00 mingetty
4 S 0 4312 1 0 75 0 - 616 schedu ? 00:00:00 kdm
4 S 0 4325 4312 1 75 0 - 38119 schedu ? 00:00:02 X
5 S 0 4326 4312 0 77 0 - 877 wait4 ? 00:00:00 kdm
4 S 12339 4352 4326 0 85 0 - 1143 rt_sig ? 00:00:00 csh
0 S 12339 4393 4352 0 79 0 - 1034 wait4 ? 00:00:00 startkde
1 S 12339 4394 4393 0 75 0 - 785 schedu ? 00:00:00 ssh-agent
1 S 12339 4436 1 0 75 0 - 5012 schedu ? 00:00:00 kdeinit
1 S 12339 4439 1 0 75 0 - 5440 schedu ? 00:00:00 kdeinit
1 S 12339 4442 1 0 75 0 - 5742 schedu ? 00:00:00 kdeinit
1 S 12339 4444 1 0 75 0 - 9615 schedu ? 00:00:00 kdeinit
0 S 12339 4454 4436 0 75 0 - 2149 schedu ? 00:00:00 artsd
1 S 12339 4474 1 0 75 0 - 10689 schedu ? 00:00:00 kdeinit
0 S 12339 4481 4393 0 75 0 - 341 schedu ? 00:00:00 kwrapper
1 S 12339 4483 1 0 75 0 - 9466 schedu ? 00:00:00 kdeinit
1 S 12339 4484 4436 0 75 0 - 9772 schedu ? 00:00:00 kdeinit
1 S 12339 4486 1 0 75 0 - 9908 schedu ? 00:00:00 kdeinit
1 S 12339 4488 1 0 75 0 - 10299 schedu ? 00:00:00 kdeinit
1 S 12339 4489 4436 0 75 0 - 5085 schedu ? 00:00:00 kdeinit
1 S 12339 4493 1 0 75 0 - 9698 schedu ? 00:00:00 kdeinit
0 S 12339 4494 4436 0 75 0 - 2942 schedu ? 00:00:00 pam-panel-i
4 S 0 4495 4494 0 75 0 - 389 schedu ? 00:00:00 pam_timesta
1 S 12339 4496 4436 0 75 0 - 9994 schedu ? 00:00:00 kdeinit
1 S 12339 4497 4436 0 75 0 - 10010 schedu ? 00:00:00 kdeinit
1 S 12339 4500 1 0 75 0 - 9503 schedu ? 00:00:00 kalarmd
0 S 12339 4501 4496 0 75 0 - 1165 rt_sig pts/2 00:00:00 csh
0 S 12339 4502 4497 0 75 0 - 1159 rt_sig pts/1 00:00:00 csh
0 S 12339 4546 4501 0 85 0 - 1039 wait4 pts/2 00:00:00 firefox
0 S 12339 4563 4546 0 85 0 - 1048 wait4 pts/2 00:00:00 run-mozilla
0 S 12339 4568 4563 1 75 0 - 20083 schedu pts/2 00:00:01 firefox-bin
0 S 12339 4573 1 0 75 0 - 1682 schedu pts/2 00:00:00 gconfd-2
0 S 12339 4583 4502 0 75 0 - 5402 schedu pts/1 00:00:00 gimp
0 S 12339 4776 4583 0 85 0 - 2140 schedu pts/1 00:00:00 script-fu
1 S 12339 4779 4436 1 75 0 - 9971 schedu ? 00:00:00 kdeinit
0 S 12339 4780 4779 0 75 0 - 1155 rt_sig pts/3 00:00:00 csh
0 R 12339 4803 4780 0 80 0 - 856 - pts/3 00:00:00 ps
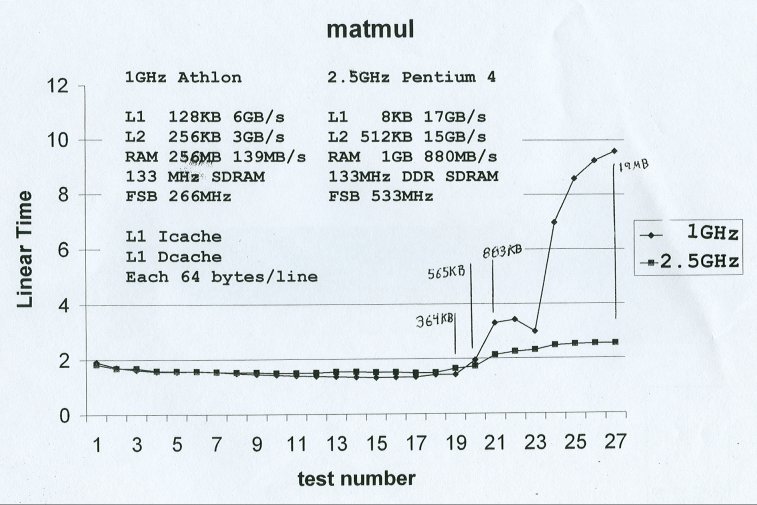
A benchmark that was designed to note discontinuity in time
as the data size increased exceeding the L1 cache, L2 cache.
It would take hours if the program exceeded RAM and went to
virtual memory on disk!
The basic code, a simple matrix times matrix multiply:
/* matmul.c 100*100 matrix multiply */
#include <stdio.h>
#define N 100
int main()
{
double a[N][N]; /* input matrix */
double b[N][N]; /* input matrix */
double c[N][N]; /* result matrix */
int i,j,k;
/* initialize */
for(i=0; i<N; i++){ /* FYI in debugger, this is line 13 */
for(j=0; j<N; j++){
a[i][j] = (double)(i+j);
b[i][j] = (double)(i-j);
}
}
printf("starting multiply \n");
for(i=0; i<N; i++){
for(j=0; j<N; j++){
c[i][j] = 0.0;
for(k=0; k<N; k++){ /* how many instructions are in this loop? */
c[i][j] = c[i][j] + a[i][k]*b[k][j]; /* most time spent here! */
/* this statement is executed one million times */
}
}
}
printf("a result %g \n", c[7][8]); /* prevent dead code elimination */
return 0;
}
The actual code:
time_matmul.c
and results:
time_matmul_1ghz.out
time_matmul_p4_25.out
time_matmul_2100.out
Test results on two computers using same executable:
Memory usage on RedHat Linux:
83 processes, 3 running
X 38,119 KB way too big for cache
Firefox 20,083 KB
Gimp 5,402 KB with extras running
etc
running top reports:
306 MB memory used
195 MB memory free
14 MB memory buff
From: ps -Al ## memory size in KB
F S UID PID PPID C PRI NI ADR SZ WCHAN TTY TIME CMD
4 S 0 1 0 1 75 0 - 345 schedu ? 00:00:04 init
1 S 0 2 1 0 75 0 - 0 contex ? 00:00:00 keventd
1 S 0 3 1 0 75 0 - 0 schedu ? 00:00:00 kapmd
1 S 0 4 1 0 94 19 - 0 ksofti ? 00:00:00 ksoftirqd_C
1 S 0 9 1 0 85 0 - 0 bdflus ? 00:00:00 bdflush
1 S 0 5 1 0 75 0 - 0 schedu ? 00:00:00 kswapd
1 S 0 6 1 0 75 0 - 0 schedu ? 00:00:00 kscand/DMA
1 S 0 7 1 0 75 0 - 0 schedu ? 00:00:00 kscand/Norm
1 S 0 8 1 0 75 0 - 0 schedu ? 00:00:00 kscand/High
1 S 0 10 1 0 75 0 - 0 schedu ? 00:00:00 kupdated
1 S 0 11 1 0 85 0 - 0 md_thr ? 00:00:00 mdrecoveryd
1 S 0 15 1 0 75 0 - 0 end ? 00:00:00 kjournald
1 S 0 73 1 0 85 0 - 0 end ? 00:00:00 khubd
1 S 0 1012 1 0 75 0 - 0 end ? 00:00:00 kjournald
1 S 0 1137 1 0 85 0 - 0 end ? 00:00:00 kjournald
1 S 0 3676 1 0 84 0 - 524 schedu ? 00:00:00 dhclient
5 S 0 3727 1 0 75 0 - 369 schedu ? 00:00:00 syslogd
5 S 0 3731 1 0 75 0 - 344 do_sys ? 00:00:00 klogd
5 S 32 3749 1 0 75 0 - 388 schedu ? 00:00:00 portmap
5 S 29 3768 1 0 75 0 - 391 schedu ? 00:00:00 rpc.statd
1 S 0 3812 1 0 75 0 - 0 end ? 00:00:00 rpciod
1 S 0 3813 1 0 85 0 - 0 schedu ? 00:00:00 lockd
5 S 0 3825 1 0 84 0 - 343 schedu ? 00:00:00 apmd
5 S 0 3841 1 0 85 0 - 5014 schedu ? 00:00:00 ypbind
1 S 0 3945 1 0 75 0 - 372 pipe_w ? 00:00:00 automount
1 S 0 3947 1 0 75 0 - 372 pipe_w ? 00:00:00 automount
1 S 0 3949 1 0 75 0 - 372 pipe_w ? 00:00:00 automount
5 S 0 3968 1 0 85 0 - 879 schedu ? 00:00:00 sshd
5 S 38 3989 1 0 75 0 - 601 schedu ? 00:00:00 ntpd
1 S 0 4013 1 0 75 0 - 0 schedu ? 00:00:00 afs_rxliste
1 S 0 4015 1 0 75 0 - 0 end ? 00:00:00 afs_callbac
1 S 0 4017 1 0 75 0 - 0 schedu ? 00:00:00 afs_rxevent
1 S 0 4019 1 0 75 0 - 0 schedu ? 00:00:00 afsd
1 S 0 4021 1 0 75 0 - 0 schedu ? 00:00:00 afs_checkse
1 S 0 4023 1 0 75 0 - 0 end ? 00:00:00 afs_backgro
1 S 0 4025 1 0 75 0 - 0 end ? 00:00:00 afs_backgro
1 S 0 4027 1 0 75 0 - 0 end ? 00:00:00 afs_backgro
1 S 0 4029 1 0 75 0 - 0 end ? 00:00:00 afs_cachetr
5 S 0 4037 1 0 75 0 - 354 schedu ? 00:00:00 gpm
1 S 0 4046 1 0 75 0 - 358 schedu ? 00:00:00 crond
5 S 43 4078 1 0 76 0 - 1226 schedu ? 00:00:00 xfs
1 S 2 4087 1 0 85 0 - 355 schedu ? 00:00:00 atd
4 S 0 4306 1 0 82 0 - 340 schedu tty1 00:00:00 mingetty
4 S 0 4307 1 0 82 0 - 340 schedu tty2 00:00:00 mingetty
4 S 0 4308 1 0 82 0 - 340 schedu tty3 00:00:00 mingetty
4 S 0 4309 1 0 82 0 - 340 schedu tty4 00:00:00 mingetty
4 S 0 4310 1 0 82 0 - 340 schedu tty5 00:00:00 mingetty
4 S 0 4311 1 0 82 0 - 340 schedu tty6 00:00:00 mingetty
4 S 0 4312 1 0 75 0 - 616 schedu ? 00:00:00 kdm
4 S 0 4325 4312 1 75 0 - 38119 schedu ? 00:00:02 X
5 S 0 4326 4312 0 77 0 - 877 wait4 ? 00:00:00 kdm
4 S 12339 4352 4326 0 85 0 - 1143 rt_sig ? 00:00:00 csh
0 S 12339 4393 4352 0 79 0 - 1034 wait4 ? 00:00:00 startkde
1 S 12339 4394 4393 0 75 0 - 785 schedu ? 00:00:00 ssh-agent
1 S 12339 4436 1 0 75 0 - 5012 schedu ? 00:00:00 kdeinit
1 S 12339 4439 1 0 75 0 - 5440 schedu ? 00:00:00 kdeinit
1 S 12339 4442 1 0 75 0 - 5742 schedu ? 00:00:00 kdeinit
1 S 12339 4444 1 0 75 0 - 9615 schedu ? 00:00:00 kdeinit
0 S 12339 4454 4436 0 75 0 - 2149 schedu ? 00:00:00 artsd
1 S 12339 4474 1 0 75 0 - 10689 schedu ? 00:00:00 kdeinit
0 S 12339 4481 4393 0 75 0 - 341 schedu ? 00:00:00 kwrapper
1 S 12339 4483 1 0 75 0 - 9466 schedu ? 00:00:00 kdeinit
1 S 12339 4484 4436 0 75 0 - 9772 schedu ? 00:00:00 kdeinit
1 S 12339 4486 1 0 75 0 - 9908 schedu ? 00:00:00 kdeinit
1 S 12339 4488 1 0 75 0 - 10299 schedu ? 00:00:00 kdeinit
1 S 12339 4489 4436 0 75 0 - 5085 schedu ? 00:00:00 kdeinit
1 S 12339 4493 1 0 75 0 - 9698 schedu ? 00:00:00 kdeinit
0 S 12339 4494 4436 0 75 0 - 2942 schedu ? 00:00:00 pam-panel-i
4 S 0 4495 4494 0 75 0 - 389 schedu ? 00:00:00 pam_timesta
1 S 12339 4496 4436 0 75 0 - 9994 schedu ? 00:00:00 kdeinit
1 S 12339 4497 4436 0 75 0 - 10010 schedu ? 00:00:00 kdeinit
1 S 12339 4500 1 0 75 0 - 9503 schedu ? 00:00:00 kalarmd
0 S 12339 4501 4496 0 75 0 - 1165 rt_sig pts/2 00:00:00 csh
0 S 12339 4502 4497 0 75 0 - 1159 rt_sig pts/1 00:00:00 csh
0 S 12339 4546 4501 0 85 0 - 1039 wait4 pts/2 00:00:00 firefox
0 S 12339 4563 4546 0 85 0 - 1048 wait4 pts/2 00:00:00 run-mozilla
0 S 12339 4568 4563 1 75 0 - 20083 schedu pts/2 00:00:01 firefox-bin
0 S 12339 4573 1 0 75 0 - 1682 schedu pts/2 00:00:00 gconfd-2
0 S 12339 4583 4502 0 75 0 - 5402 schedu pts/1 00:00:00 gimp
0 S 12339 4776 4583 0 85 0 - 2140 schedu pts/1 00:00:00 script-fu
1 S 12339 4779 4436 1 75 0 - 9971 schedu ? 00:00:00 kdeinit
0 S 12339 4780 4779 0 75 0 - 1155 rt_sig pts/3 00:00:00 csh
0 R 12339 4803 4780 0 80 0 - 856 - pts/3 00:00:00 ps
A benchmark that was designed to note discontinuity in time
as the data size increased exceeding the L1 cache, L2 cache.
It would take hours if the program exceeded RAM and went to
virtual memory on disk!
The basic code, a simple matrix times matrix multiply:
/* matmul.c 100*100 matrix multiply */
#include <stdio.h>
#define N 100
int main()
{
double a[N][N]; /* input matrix */
double b[N][N]; /* input matrix */
double c[N][N]; /* result matrix */
int i,j,k;
/* initialize */
for(i=0; i<N; i++){ /* FYI in debugger, this is line 13 */
for(j=0; j<N; j++){
a[i][j] = (double)(i+j);
b[i][j] = (double)(i-j);
}
}
printf("starting multiply \n");
for(i=0; i<N; i++){
for(j=0; j<N; j++){
c[i][j] = 0.0;
for(k=0; k<N; k++){ /* how many instructions are in this loop? */
c[i][j] = c[i][j] + a[i][k]*b[k][j]; /* most time spent here! */
/* this statement is executed one million times */
}
}
}
printf("a result %g \n", c[7][8]); /* prevent dead code elimination */
return 0;
}
The actual code:
time_matmul.c
and results:
time_matmul_1ghz.out
time_matmul_p4_25.out
time_matmul_2100.out
Test results on two computers using same executable:
 A fact you should know about memory usage:
If your program gets more memory while running, e.g. using malloc,
then tries to release that memory when not needed, e.g. free,
the memory still belongs to your process. The memory is not
given back to the operating system for use by another program.
Thus, some programs keep growing in size as they run. Hopefully,
internally, reusing any memory they previously freed.
On Linux you can use cat /proc/cpuinfo to see brief cache size
CS machine cpuinfo
source code time_mp8.c
measured time_mp8.out
We have seen the Intel P4 architecture, and here is a view of
the AMD Athlon architecture circa 2001.
9 pipelines, possibly 9 instruction issued per clock, 3 is typical.
A fact you should know about memory usage:
If your program gets more memory while running, e.g. using malloc,
then tries to release that memory when not needed, e.g. free,
the memory still belongs to your process. The memory is not
given back to the operating system for use by another program.
Thus, some programs keep growing in size as they run. Hopefully,
internally, reusing any memory they previously freed.
On Linux you can use cat /proc/cpuinfo to see brief cache size
CS machine cpuinfo
source code time_mp8.c
measured time_mp8.out
We have seen the Intel P4 architecture, and here is a view of
the AMD Athlon architecture circa 2001.
9 pipelines, possibly 9 instruction issued per clock, 3 is typical.
 You can find out your computers cache sizes and speeds:
www.memtest86.com
Get the .bin file to make a bootable floppy
Get the .iso file to make a bootable CD
As part of the output, you do not have to run the memory test,
you will see cache sizes and bandwidth values. (Shown on plot above.)
You can find out your computers cache sizes and speeds:
www.memtest86.com
Get the .bin file to make a bootable floppy
Get the .iso file to make a bootable CD
As part of the output, you do not have to run the memory test,
you will see cache sizes and bandwidth values. (Shown on plot above.)
The "cache" is very high speed memory on the CPU chip.
Typical CPU's can get words out of the cache every clock.
In order to be as fast as the logic on the CPU, the cache
can not be as large as the main memory. Typical cache sizes
are hundreds of kilobytes to a few megabytes.
There is typically a level 1 instruction cache, a level 1
data cache. These would be in the blocks on our project
schematic labeled instruction memory and data memory.
Then, there is typically a level 2 unified cache that is
larger and may be slower than the level 1 caches. Unified
means it is used for both instructions and data.
Some computers have a level 3 cache that is larger and
slower than the level 2 cache. Multi core computers
have at least a L1 instruction cache and a L1 data cache
for every core. Some have a L3 unified cache that is
available to all cores. Thus data can go from one core
to another without going through RAM.
+-----------+ +-----------+
| L1 Icache | | L1 Dcache |
+-----------+ +-----------+
| |
+---------------------------+
| L2 unified cache |
+---------------------------+
|
+------+
| RAM |
+------+
|
+------+
| Disc | or Solid State Drive, SSD
+------+
The goal of the architecture is to use the cache for instructions
and data in order to execute instructions as fast as possible.
Typical RAM requires 5 to 10 clocks to get an instruction or
data word. A typical CPU does prefetching and branch prediction
to bring instructions into the cache in order to minimize
stalls waiting for instructions. You will simulate a cache and
the associated stalls in part 3 of your project.
Intel IA-64 cache structure, page 3
IA-64 Itanium
An approximate hierarchy is:
size response
CPU 0.5 ns 2 GHz clock
L1 cache .032MB 0.5 ns one for instructions, another for data
L2 cache 4MB 1.0 ns
RAM 4000MB 4.0 ns
disk 500000MB 4.0 ms = 4,000,000 ns
A program is loaded from disk, into RAM, then as needed
into L2 cache, then as needed into L1 cache, then as needed
into the CPU pipelines.
1) The CPU initiates the request by sending the L1 cache an address.
If the L1 cache has the value at that address, the value is quickly
sent to the CPU.
2) If the L1 cache does not have the value, the address is passed to
the L2 cache. If the L2 cache has the value, the value is quickly
passed to the L1 cache. The L1 cache passes the value to the CPU.
3) If the L2 cache does not have the value at the address, the
address is passed to a memory controller that must access RAM
in order to get the value. The value passes from RAM, through
the memory controller to the L2 cache then to the L1 cache then
to the CPU.
This may seem tedious yet each level is optimized to provide good
performance for the total system. One reason the system is fast is
because of wide data paths. The RAM data path may be 128-bits or
256-bits wide. This wide data path may continue through the
L2 cache and L1 cache. The cache is organized in blocks
(lines or entries may be used in place of the word blocks)
that provide for many bytes of data to be accessed in parallel.
When reading from a cache, it is like combinational logic, it
is not clocked. When writing into a cache it must write on
a clock edge.
A cache receives an address, a computer address, a binary number.
The parts of the cache are all powers of two. The basic unit of
an address is a byte. For our study, four bytes, one word, will
always be fetched from the cache. When working the homework
problems be sure to read the problem carefully to determine if
the addresses given are byte addresses or word addresses.
It will be easiest and less error prone if all addresses are
converted to binary for working the homework.
The basic elements of a cache are:
A valid bit: This is a 1 if values are in the cache block
A tag field: This is the upper part of the address for
the values in the cache block.
Cache block: The values that may be instructions or data
In order to understand a simple cache, follow the sequence of word
addresses presented to the following cache.
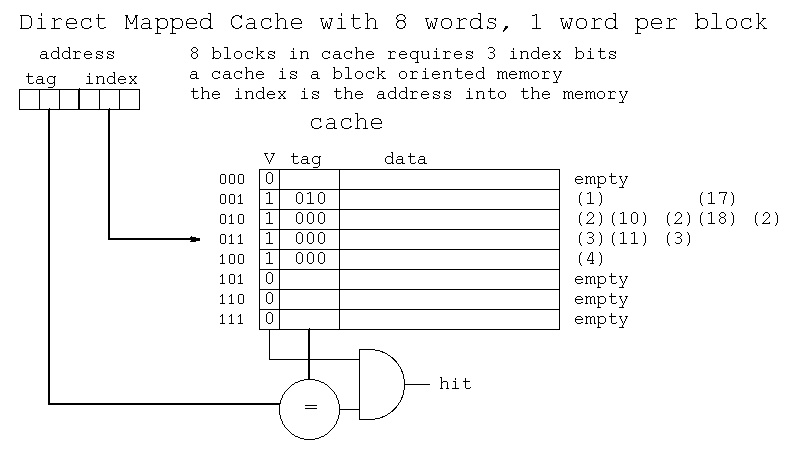 Sequence of addresses and cache actions
decimal binary hit/miss action
tag index
1 000 001 miss set valid, load data
2 000 010 miss set valid, load data
3 000 011 miss set valid, load data
4 000 100 miss set valid, load data
10 001 010 miss wrong tag, load data
11 001 011 miss wrong tag, load data
1 000 001 hit no action
2 000 010 miss wrong tag, load data
3 000 011 miss wrong tag, load data
17 010 001 miss wrong tag, load data
18 010 010 miss wrong tag, load data
2 000 010 miss wrong tag, load data
3 000 011 hit no action
4 000 100 hit no action
Sequence of addresses and cache actions
decimal binary hit/miss action
tag index
1 000 001 miss set valid, load data
2 000 010 miss set valid, load data
3 000 011 miss set valid, load data
4 000 100 miss set valid, load data
10 001 010 miss wrong tag, load data
11 001 011 miss wrong tag, load data
1 000 001 hit no action
2 000 010 miss wrong tag, load data
3 000 011 miss wrong tag, load data
17 010 001 miss wrong tag, load data
18 010 010 miss wrong tag, load data
2 000 010 miss wrong tag, load data
3 000 011 hit no action
4 000 100 hit no action
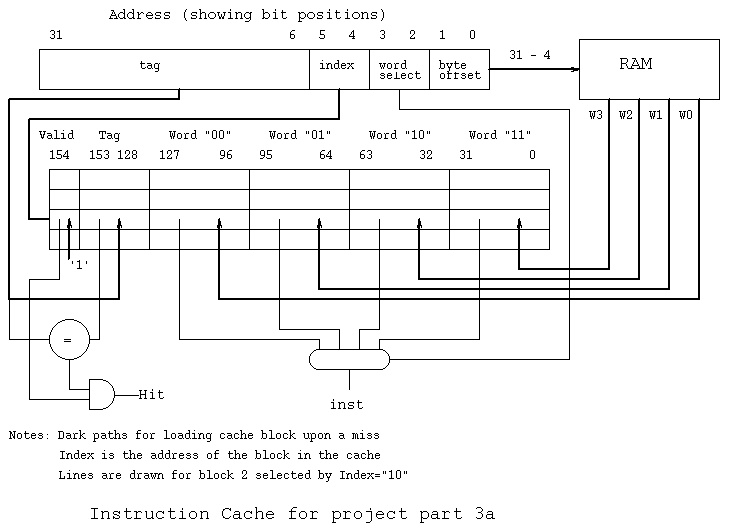 Sequence of addresses and cache actions
decimal binary hit/miss action
tag index word
1 00 00 01 miss set valid, load data (0)(1)(2)(3)
2 00 00 10 hit no action
3 00 00 11 hit no action
4 00 01 00 miss set valid, load data (4)(5)(6)(7)
10 00 10 10 miss set valid, load data (8)(9)(10)(11)
11 00 10 11 hit no action
1 00 00 01 hit no action
2 00 00 10 hit no action
3 00 00 11 hit no action
17 01 00 01 miss wrong tag, load data (16)(17)(18)(19)
18 01 00 10 hit no action
2 00 00 10 miss wrong tag, load data (0)(1)(2)(3)
3 00 00 11 hit no action
4 00 01 00 hit no action
There are many cache organizations. The ones you should know are:
A direct mapped cache: the important feature is one tag comparator.
An associative cache: the important feature is more than one tag
comparator. "Two way associative" means two
tag comparators. "Four way associative means
four tag comparators.
A fully associative cache: Every tag slot has its own comparator.
This is expensive, typically used for TLB's.
For each organization the words per block may be some power of 2.
For each organization the number of blocks may be some power of 2.
The size of the address that the cache must accept is determined by
the CPU. Note that the address is partitioned starting with the
low order bits. Given a byte address, the bottom two bits do
not go to the cache. The next bits determine the word. If there
are 4 words per block, 2-bits are needed, if there are 8 words per
block, 3-bits are needed, if there are 16 words per block 4-bits
are needed. 2^4=16 or number of bits is log base 2 of number of words.
The next bits are called the index and basically address a block.
For 2^n blocks, n bits are needed. The top bits, whatever is not
in the byte, word or index are the tag bits.
Given a 32-bit byte address, 8 words per block, 4096 blocks you would
have: byte 2-bits
word 3-bits
index 12-bits
tag 15-bits
---- +-----+-------+------+------+
total 32-bits | tag | index | word | byte | address
+-----+-------+------+------+
15 12 3 2
To compute the number of bits in this cache:
4096 x 8 words at 32 bits per word = 1,048,576
4096 x 15 bits tags = 61,440
4096 x 1 bits valid bits = 4,096
----------
total bits = 1,114,112 (may not be a power 0f 2)
Each cache block or line or entry, for this example has:
valid tag 8 words data or instructions
+-+ +----+ +----------------------------+
|1| | 15 | | 8*32=256 bits | total 272 bits
+-+ +----+ +----------------------------+
then 12 bit index means 2^12=4096 blocks. 4096 * 272 = 1,114,112 bits.
Cache misses may be categorized by the reason for the miss:
Compulsory miss: The first time a word is used and the block that
contains that word has never been used.
Capacity miss: A miss that would have been a hit if the cache was big enough.
Conflict miss: A miss that would have been a hit in a fully associative cache.
The "miss penalty" is the time or number of clocks that are required to
get the data value.
Data caches have two possible architectures in addition to all
other variations. Consider the case where the CPU is writing
data to RAM, our store word instruction. The data actually is
written into the L1 data cache by the CPU. There are now
two possibilities:
Write back cache: the word is written to the cache. No memory access
is made until the block where the word is written
is needed, at which time the entire block is
written to RAM. It is possible the word could be
written, and read, many times before any memory access.
Write through cache: the word is written to the cache and the single
word is sent to the RAM memory. This causes to
RAM memory to be accessed on every store word but
there is no block write when the block is needed
for other data. Most of the memory bandwidth
is wasted on a wide 128 or 256 bit memory bus.
Tradeoff: Some motherboards have a jumper that you can change to
have a write back or write through cache. My choice is
a write back cache because I find it gives my job mix
better performance.
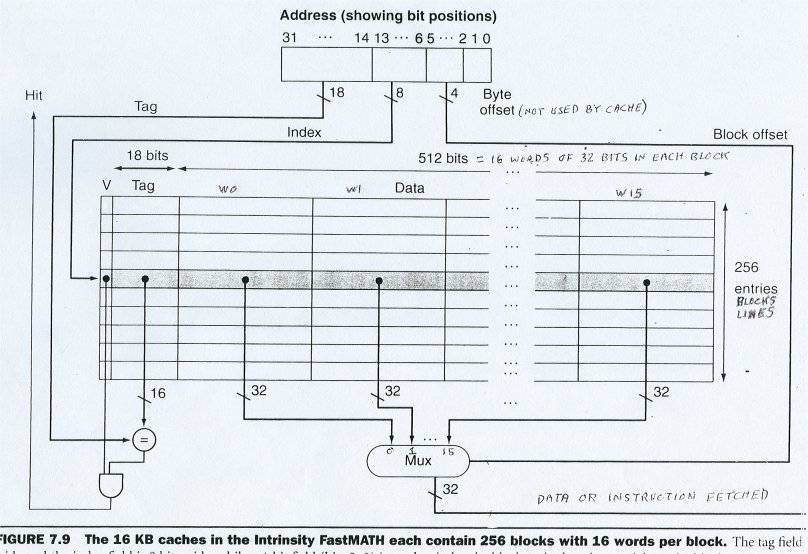
16 words per block. Note partition of address bits.
Sequence of addresses and cache actions
decimal binary hit/miss action
tag index word
1 00 00 01 miss set valid, load data (0)(1)(2)(3)
2 00 00 10 hit no action
3 00 00 11 hit no action
4 00 01 00 miss set valid, load data (4)(5)(6)(7)
10 00 10 10 miss set valid, load data (8)(9)(10)(11)
11 00 10 11 hit no action
1 00 00 01 hit no action
2 00 00 10 hit no action
3 00 00 11 hit no action
17 01 00 01 miss wrong tag, load data (16)(17)(18)(19)
18 01 00 10 hit no action
2 00 00 10 miss wrong tag, load data (0)(1)(2)(3)
3 00 00 11 hit no action
4 00 01 00 hit no action
There are many cache organizations. The ones you should know are:
A direct mapped cache: the important feature is one tag comparator.
An associative cache: the important feature is more than one tag
comparator. "Two way associative" means two
tag comparators. "Four way associative means
four tag comparators.
A fully associative cache: Every tag slot has its own comparator.
This is expensive, typically used for TLB's.
For each organization the words per block may be some power of 2.
For each organization the number of blocks may be some power of 2.
The size of the address that the cache must accept is determined by
the CPU. Note that the address is partitioned starting with the
low order bits. Given a byte address, the bottom two bits do
not go to the cache. The next bits determine the word. If there
are 4 words per block, 2-bits are needed, if there are 8 words per
block, 3-bits are needed, if there are 16 words per block 4-bits
are needed. 2^4=16 or number of bits is log base 2 of number of words.
The next bits are called the index and basically address a block.
For 2^n blocks, n bits are needed. The top bits, whatever is not
in the byte, word or index are the tag bits.
Given a 32-bit byte address, 8 words per block, 4096 blocks you would
have: byte 2-bits
word 3-bits
index 12-bits
tag 15-bits
---- +-----+-------+------+------+
total 32-bits | tag | index | word | byte | address
+-----+-------+------+------+
15 12 3 2
To compute the number of bits in this cache:
4096 x 8 words at 32 bits per word = 1,048,576
4096 x 15 bits tags = 61,440
4096 x 1 bits valid bits = 4,096
----------
total bits = 1,114,112 (may not be a power 0f 2)
Each cache block or line or entry, for this example has:
valid tag 8 words data or instructions
+-+ +----+ +----------------------------+
|1| | 15 | | 8*32=256 bits | total 272 bits
+-+ +----+ +----------------------------+
then 12 bit index means 2^12=4096 blocks. 4096 * 272 = 1,114,112 bits.
Cache misses may be categorized by the reason for the miss:
Compulsory miss: The first time a word is used and the block that
contains that word has never been used.
Capacity miss: A miss that would have been a hit if the cache was big enough.
Conflict miss: A miss that would have been a hit in a fully associative cache.
The "miss penalty" is the time or number of clocks that are required to
get the data value.
Data caches have two possible architectures in addition to all
other variations. Consider the case where the CPU is writing
data to RAM, our store word instruction. The data actually is
written into the L1 data cache by the CPU. There are now
two possibilities:
Write back cache: the word is written to the cache. No memory access
is made until the block where the word is written
is needed, at which time the entire block is
written to RAM. It is possible the word could be
written, and read, many times before any memory access.
Write through cache: the word is written to the cache and the single
word is sent to the RAM memory. This causes to
RAM memory to be accessed on every store word but
there is no block write when the block is needed
for other data. Most of the memory bandwidth
is wasted on a wide 128 or 256 bit memory bus.
Tradeoff: Some motherboards have a jumper that you can change to
have a write back or write through cache. My choice is
a write back cache because I find it gives my job mix
better performance.
16 words per block. Note partition of address bits.
 A four way associative cache. Note four comparators.
Each of the four caches could be any of the above architectures
and sizes.
A four way associative cache. Note four comparators.
Each of the four caches could be any of the above architectures
and sizes.
No comments:
Post a Comment