Terminology
- A system consists of a set of hardware and software components and is designed to provide a specified service.
- Failure of a system occurs when the system does not perform its services in the manner specified.
- An erroneous state of the system is a state which could lead to a system failure by a sequence of valid state transitions
- A fault is an anomalous physical condition.
- An error is a manifestation of a fault in a system, which can lead to system failure.
Recovery
- Failure recovery is a process that restores an erroneous state to an error-free state. (after a failure, restoring system to its "normal" state)
Failure Classification
- process failure
- system failure
- secondary storage failure
- communication medium failure
Tolerating Process Failures
- signal process to recover internally
- restart process from a prior state
- abort process
Recovering from System Failures
- amnesia -- restart in predefined state
- partial amnesia -- reset part of the state to predefined
- pause -- roll back to before failure
- halting -- give up
Tolerating Secondary Storage Failures
- archiving (periodic backup)
- mirroring (continuous)
- activity logging
Tolerating Communication Medium Failures
- ack & resend
- more complex fault-tolerant algorithms
Backward versus Forward Error Recovery
- skip forward to a new correct state
- requires contextual knowledge of what "forward" is
- go back to a previous correct state
- overhead: takes time to save and restore state
- fault may repeat (¥ cycling)
- recovery may be impossible
Backward Error Recovery
- based on recovery points
- two approaches:
- operation-based recovery
- state-based recovery
System Model
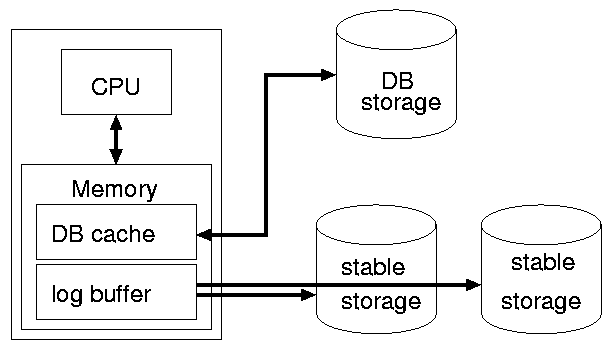
Stable Storage
- does not lose information in the event of system failure
- is used to keep logs & recovery points
- algorithms in this chapter assume an underlying stable storage system already exists
Two Approaches to Fault Tolerance
- operation based
- record a log (audit trail) of the operations performed
- restore previous state by reversing steps
- state based
- record a snapshot of the state (checkpoint)
- restore state by reloading snapshot (rollback)
Fundamental Issues in Crash Recovery
- disk writes are only atomic by sector
- updates and commits require multiple writes
- a crash may occur between writes
- log contains record of updates, commits, and aborts
- data is written to disk asynchronously
- DB is cached
- log is buffered
Basic Deferred-Update Model
- save a transaction's updates as it runs, in temporary storage
- use the saved updates to update the database when the transaction commits
- update: record a redo record (e.g. the new value of the item being updated) in an intention list
- read: combine the intention list and the database to determine the desired value
- commit: update the database by applying the intention list in order, starting with the first operation done by the transaction
- abort: discard the transaction's intention list
Basic Update-In-Place Model
- update the DB as transaction runs
- undo the updates if the transaction aborts
- update: record an undo record (e.g., the old value of the item being updated) to an undo log, and then update the database
- read:
- commit: discard the transaction's undo log
- abort: use the undo records in the transaction's undo log to back out the transaction's updates, by backing out the operations in the reverse of the order in which they were originally done
Extended Update-In-Place Model
- update: modify the online DB and record both undo and redo records, including:
- name/location of object
- old state/value of object (for undo)
- new state/value of object (for redo)
- read: read the current value and apply the transaction's undo log
- commit: discard/invalidate the transaction's undo log
- abort: use the undo records in the transaction's undo log to back out the transaction's updates
Crash Recovery with Update-In-Place
We now have a way to reconstruct the DB system in event of a crash, starting from an archived snapshot and the subsequent log:- transactions not logged as committed are treated as aborted
- back out active or aborted transactions, using undo records
- do DB updates that may have been in cache, using redo records
Problem: DB write before log write
There is a defect in the above scheme- if the cached new value of X is written to DB on disk
- and then the system crashes, before the old value of X is written to log
Solution: Write-Ahead-Log
Before a block is written to DB disk, make sure the corresponding undo record is completely written to the log disk.The log must be forced to disk as part of committing a transaction.
Crash Recovery with Write-Ahead-Log
- redo phase: redo all the updates in the log, including undo operations of aborted transactions
- undo phase: abort all transactions that have no commit or abort record in the log, using the usual undo records in the log
State Based Approach
- based on checkpoints of entire state of process
- recovery does rollback to checkpointed state
- use of shadow pages can reduce size of checkpoints
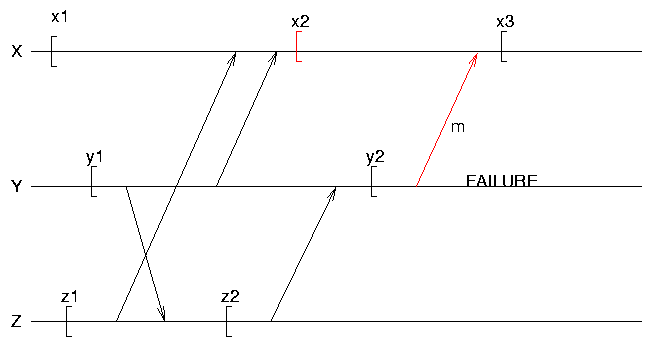
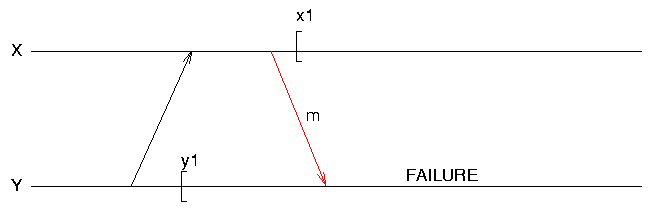
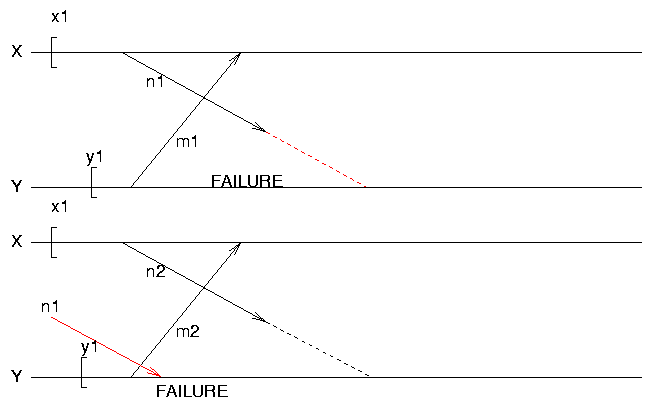
Problems in Distributed/Concurrent Systems
- communicating processes must coordinate checkpoints & rollbacks
- lost messages
- orphan messages
- livelocks
Orphan Messages
Lost Messages
Livelock
Strongly Consistent Set of Checkpoints
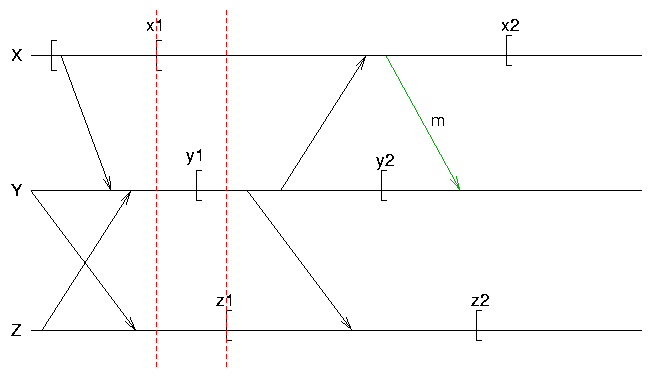
Consistent Set of Checkpoints
What is the remaining problem here?
No comments:
Post a Comment